
Lab 6 Linear Regression
6.2 Lab Skills Learned
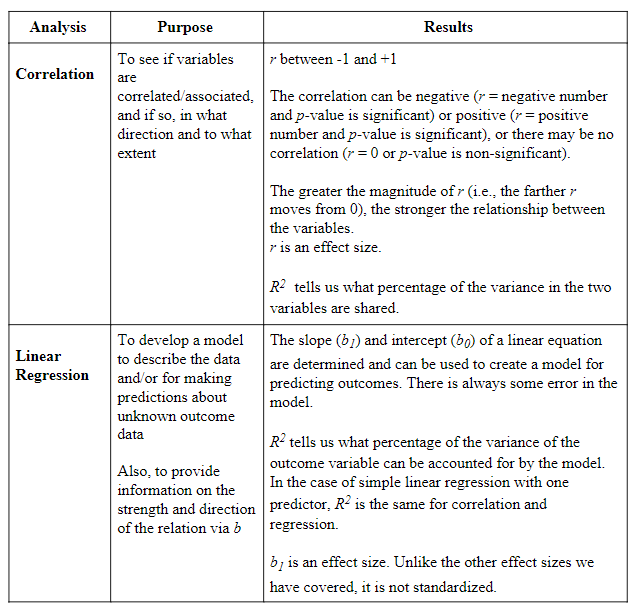
In this lab, we will use JAMOVI to conduct a simple linear regression. We will learn how to:
- Request the statistical information for building a model to predict an outcome variable
- Read the results to interpret if the model is more helpful than knowing the mean
- Build the model with those statistics if appropriate
6.3 Important Stuff
- citation: Schroeder, J., & Epley, N. (2015). The sound of intellect: Speech reveals a thoughtful mind, increasing a job candidate’s appeal. Psychological Science, 26(6), 877–891.
- Link to article
6.4 Background
6.4.1 Assumptions of linear regression
As linear regression is a parametric analysis, there are assumptions which must be met for the results of the analysis to make sense. The assumptions of linear regression include:
1. Linearity: Outcome variable should be linearly related to the predictor variable. (Question: Based on what you have learned thus far, how do you believe we can check this assumption?)
2. Independent Errors: For any 2 observations, the residual terms should be uncorrelated.
3. Homoscedasticity (AKA homogeneity of variance): The variability in the outcome variable around the regression line should be the same for all values of the predictor variable.
4. Normally Distributed Errors: The residuals in the model are normally distributed with a mean of 0.
6.5 Checking one assumption before conducting the analysis
Before we conduct the analysis, we can check the first assumption using a scatterplot. Click Analyses, Exploration, and Scatterplot. Move one variable to Y-Axis field and the other variable to X-Axis field.
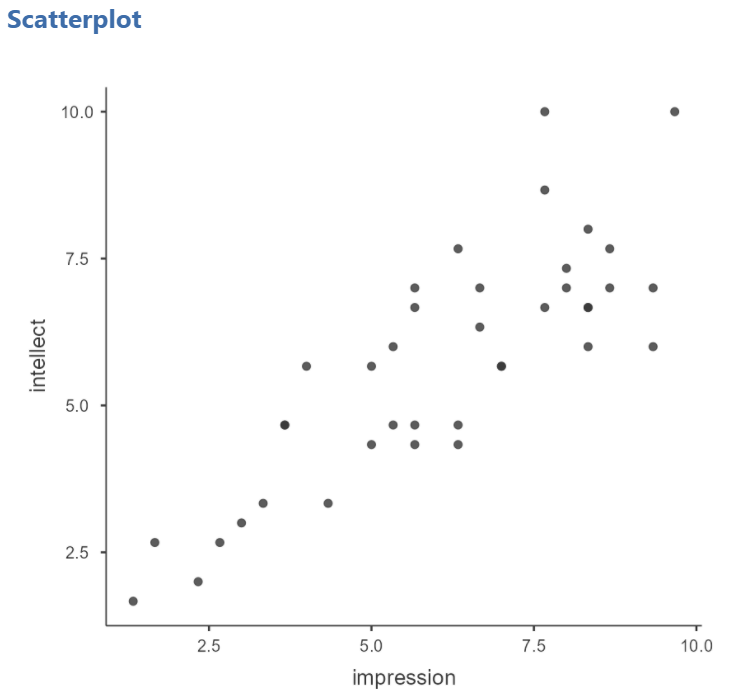
Remember: At this point, you can look at the scatterplot with either variable on the x-axis, but typically, as we progress and talk about predictor variables and outcome variables, we would place the predictor variable on the x-axis and the outcome variable on the y-axis. Also, you can add the line of best fit if you select Linear under Regression Line in the Analysis panel.

Looking at the resulting graph (depicted above), do you feel the assumption of linearity is met or violated?
We can consider whether the data meet the other assumptions while conducting the analysis in JAMOVI.
6.6 Conducting the analysis
To request linear regression, click Analyses, Regression, and Linear Regression. Move the outcome variable to the Dependent Variable field. In our example, intellect is the outcome variable. Move the predictor variable to the to the Covariates window if the variable is measured on at least an interval scale or to the Factors window if the variable is measured on an ordinal or nominal scale).. In our example, impression is the predictor variable, it is measured at least at the interval scale, and we will place it in the Covariates window.
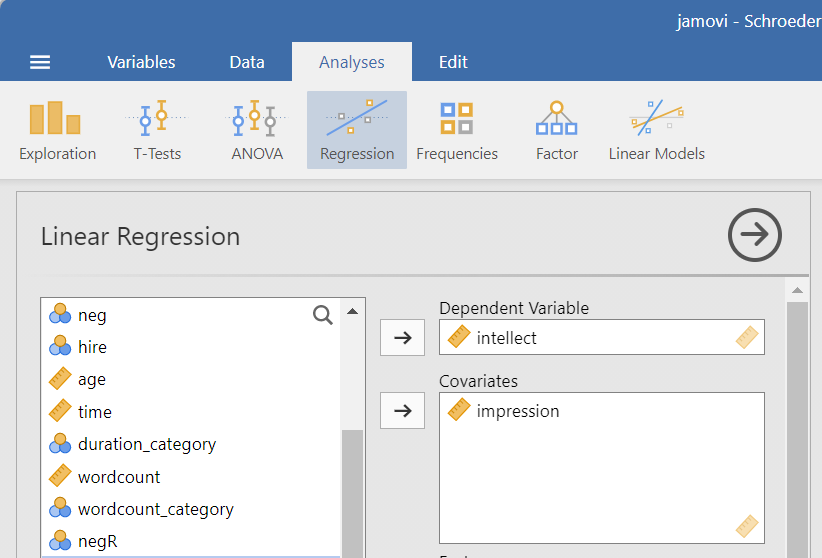
Before we start interpreting the model, we should return to checking assumptions. Under the Assumption Checks ribbon, click to seleect the Autocorrelation test, the Q-Q Plot, and the Residuals plot.
Recall that for the independence of error assumption, we indicated, for any two observations, the residual terms should be uncorrelated (or independent). When we selected Autocorrelation test, the Durbin-Watson test was conducted, and its results are displayed in the Results panel. When interpreting these results, know a value for the “DW Statistic” (as it is labeled in the table) close to 2 would indicate the assumption is upheld. Values less than 1 or greater than 3 are problematic and indicate we are violating this assumption. We also look at the p-value. A p-value representing a significant result (p < .05) indicates a violation of the assumption.
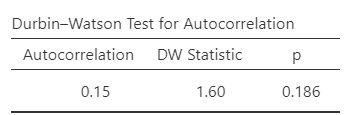
Question: Given the DW statistic value is 1.60 and the p-value is .186, is the assumption of independent errors met or violated?
For the assumption of homoscedasticity to be upheld, the variance of the residual terms should be constant at each level of the predictor vatriance. We will look to the Residuals plot. Notice that JAMOVI provides one plot of the overall model (Fitted) and one for each of your variables (predictor and outcomes). We will focus on the fitted plot. To meet the assumption, the residuals should appear as a random scattering of dots – evenly dispersed around 0 on the y-axis. Residuals appearing to be distributed in a funnel shape – with a wide spread on one end of the x-axis and a narrow spread on the other end of that axis – suggests a violation to the assumption of homoscedasticity.
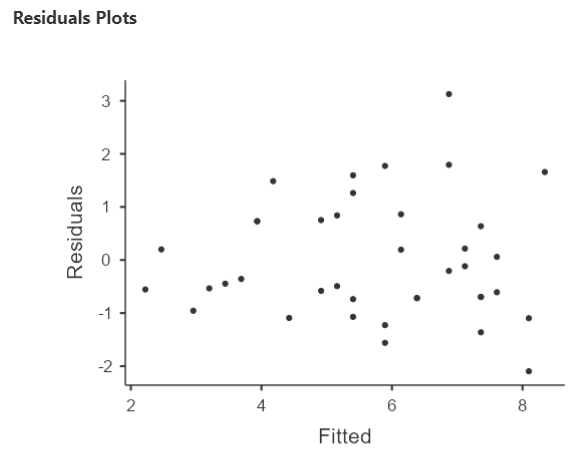
Question: Given given the distribution of the residuals, is the assumption of homoscedasticity met or violated?
To determine whether the residuals are normally distributed, we can look at the Q-Q plot of the residuals. You may recall from earlier lessons about checking your data that the more closely the data (in this case the residual terms) hover around the line in a Q-Q plot, the more confidence we have that they are normally distributed.
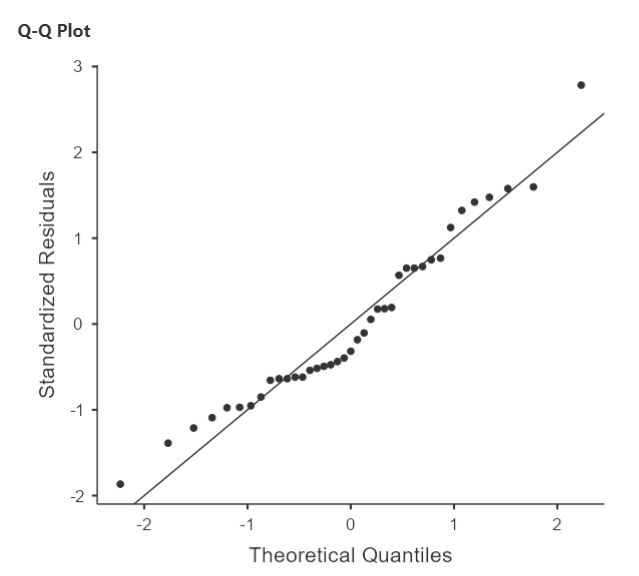
Question: Considering where the residual terms are located in relation to the line, is the assumption of normality of the residual terms met or violated?
If we feel confident about meeting the assumptions, we can continue with the linear regression analysis. Having used the Analyses, Regression, and Linear Regression commands, two tables were generated in the Results panel.
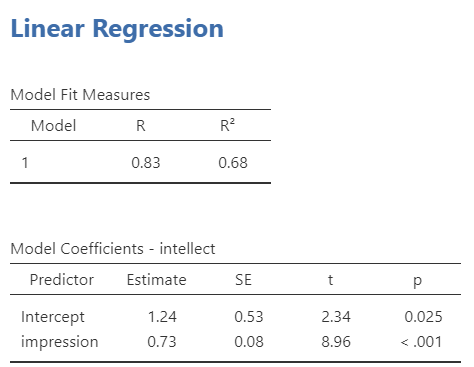
The R2 term in the first table tells us what percentage of the variance of the outcome variable can be accounted for by the model. According to our results, this linear regression model based on impression would account for 68% of the variance of intellect. The second table tells us about the slope of our regression line. We see that the p-value for the slope is significantly different from zero when we read the line for impression, where p < .001.
We also want to be sure that this model is better than simply knowing and using the mean to make our predictions. As such, under the Model Coefficients ribbon, select the ANOVA test under Omnibus Test. The following table should appear in your Results panel:

Looking at the p-value, we see a significant result. As such, we have reason to believe this model has more predictive power than simply knowing the mean.
6.7 Developing the regression model from the statistics
You likely remember the linear equation from previous education: y = mx + b. The regression model (or equation) is derived from the linear equation, where b0 represents the intercept of the line, b1 represents the slope of the line, and Ɛi represents the error in the model.
Ŷi = (b0 + b1Xi) + Ɛi
Estimate of Outcome Variable = b0 + b1(Predictor Variable) + Ɛi
Estimate of intellect = 1.24 + 0.73(impression) + Ɛi
6.8 Reporting the Results
A regression model was created and is significant [F(1, 37) = 80.32, p < .0001].
This model can account for approximately 68% of the variability in Intellect scores (R2 = .69). The slope of the regression line was significantly different from zero (B = 0.73, t(37) = 8.96, p < .0001).
6.9 Homework
See Moodle