
Chapter 6 Lab 6: Correlation
If … we choose a group of social phenomena with no antecedent knowledge of the causation or absence of causation among them, then the calculation of correlation coefficients, total or partial, will not advance us a step toward evaluating the importance of the causes at work. -Sir Ronald Fisher
In lecture and in the textbook, we have been discussing the idea of correlation. This is the idea that two things that we measure can be somehow related to one another. For example, your personal happiness, which we could try to measure say with a questionnaire, might be related to other things in your life that we could also measure, such as number of close friends, yearly salary, how much chocolate you have in your bedroom, or how many times you have said the word Nintendo in your life. Some of the relationships that we can measure are meaningful, and might reflect a causal relationship where one thing causes a change in another thing. Some of the relationships are spurious, and do not reflect a causal relationship.
In this lab you will learn how to compute correlations between two variables in software, and then ask some questions about the correlations that you observe.
6.1 General Goals
- Compute Pearson’s r between two variables using software
- Discuss the possible meaning of correlations that you observe
6.2 JAMOVI - Week 12 - April 1st, 2nd, & 3rd - For PSYC 292 Students
Some of this section is copied almost verbatim, with some editorial changes, from Answering questions with data: The lab manual for R, Excel, SPSS and JAMOVI, Lab 3, Section 3.4, SPSS, according to its CC license. Thank you to Crump, Krishnan, Volz, & Chavarga (2018).
In this lab, we will use jamovi to calculate the correlation coefficient. We will focus on the most commonly used Pearson’s coefficient, r. We will learn how to:
- Calculate the Pearson’s r correlation coefficient for bivariate data
- Produce a correlation matrix, reporting Pearson’s r for more than two variables at a time
- Produce a scatterplot
- Applying a filter to the data set for further analysis
6.2.1 Pre-lab reading and tasks
6.2.1.1 Assumptions of correlation
This lab will focus on Pearson’s correlation. For the calculation to make sense, the data must meet certain criteria. These are known as the assumptions of Pearson’s correlation.
Pearson’s correlation assumes:
There is a linear relation between the two variables. For this to be assessed, the scale of measurement of both variables must be at least interval. You cannot assess whether the relation is linear without equal spacing between intervals. Do not run Pearson’s correlation on nominal or ordinal variables.
There are no outliers. We are not going to get too much into outliers. If you have a point in your data set that is really far away from the other points, you might have an outlier.
Field, A (2018) Discovering Statistics Using IMB SPSS Statistics, 5th edition. Sage: California.
Additionally, if you want to look at the p-value associated with Pearson’s correlation (i.e., if you want to make inferences), the data must adhere to the normality assumption. If your sample size is large, you don’t need to worry about normality. If your sample size is small, you should check that your variables are normally distributed.
6.2.1.2 Download and open data
For the purpose of this lab, a version of the PSYC 291 survey data that contains “composite” scores for a few variables has been created. Remember composite scores are generated by combining other variables together. For example, the anxiety composite score was generated by averaging all the responses to survey questions about anxiety after reverse coding items that were “negatively” worded. Composite scores are very useful if you are interested in a construct that cannot be defined by a single question.
If you completed the Terms of Use quiz successfully, you gained access to downloading the other version of this data set,“PSYC 291 Survey Data_2026_Version2_updated”. (Remember to open JAMOVI, and then open the downloaded file within the program if your computer does not allow you to open the file by double-clicking on the file name.)
6.2.2 Correlation Coefficient for Bivariate Data
Bivariate is a fancy way of saying two variables. Let’s say you were interested in the relationship between two variables: sleep quality and anxiety at the start of the semester. To calculate a correlation in JAMOVI, go to Analyses -> Regression -> Correlation Matrix:
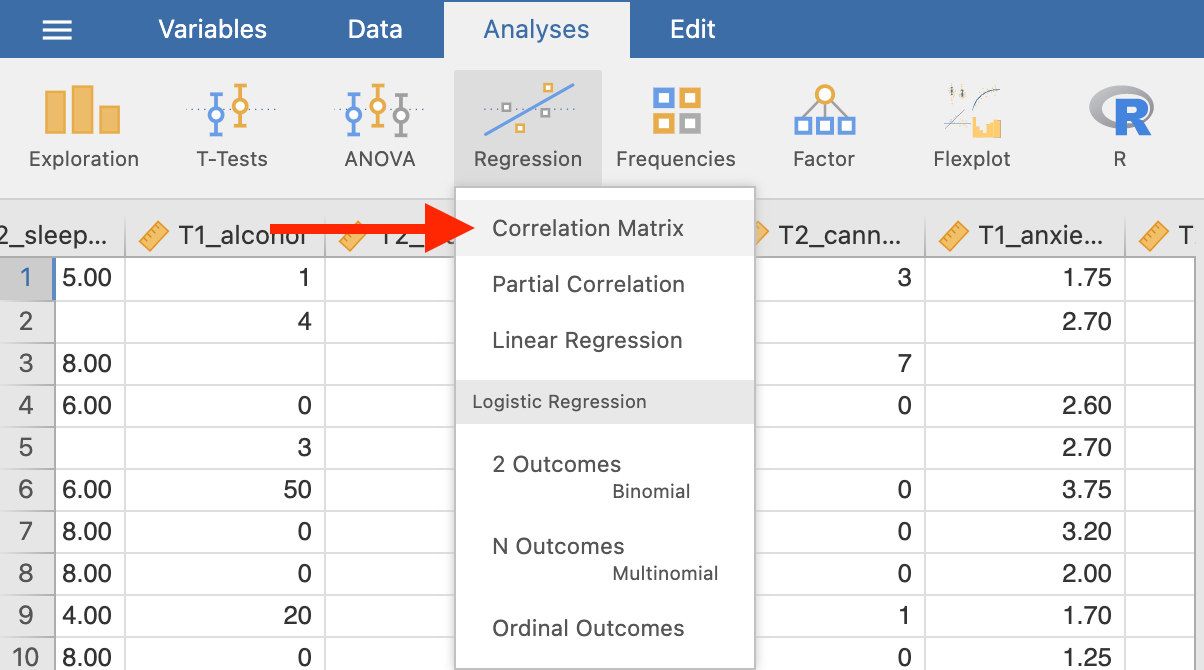
Move your variables of interest, T1_sleep_quality_composite and T1_anxiety_composite, to the right box:
An output table will be generated in the results panel:

The table indicates that Pearson’s r between the two variables is -0.43, with a p-value of less than .001. This is a negative correlation: as one variable goes up, the other goes down. Note: We know the correlation is significant because the p-value of less than .001, and we know the correlation is negative because the correlation coefficient, r, is a negative value.
6.2.3 Correlation Matrix
In the event that you have more than two variables in your spreadsheet, and would like to evaluate correlations between several variables taken two at a time, you can enter multiple variables into the correlation window and obtain a correlation matrix. The correlation matrix is a table showing every possible bivariate correlation among a group of variables.
Let’s add T1_sleep_hours to our correlation matrix. First move the variable to the right box:
Now the output panel has three sets of results:
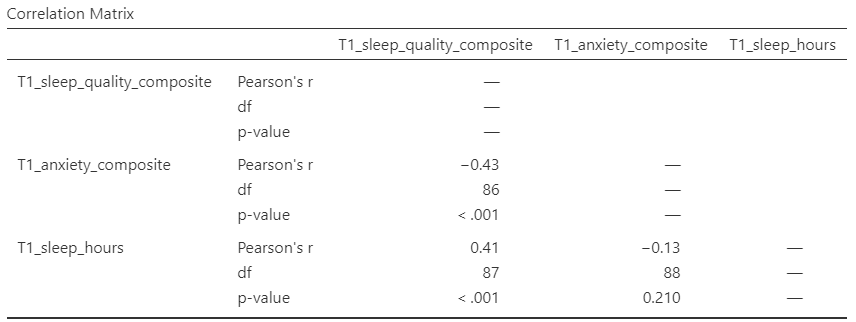
Note that some of the correlations are negative, and some are positive. Some are significant (with p < .05) and some are not (with p > .05).
6.2.4 APA format reporting of a correlation
Recall the output for the correlation between T1_sleep_quality_composite and T1_anxiety_composite:
Return to the Analysis panel (by clicking on the correlation matrix in the Results panel) and click to request the “Confidence intervals” under Additional Statistics.
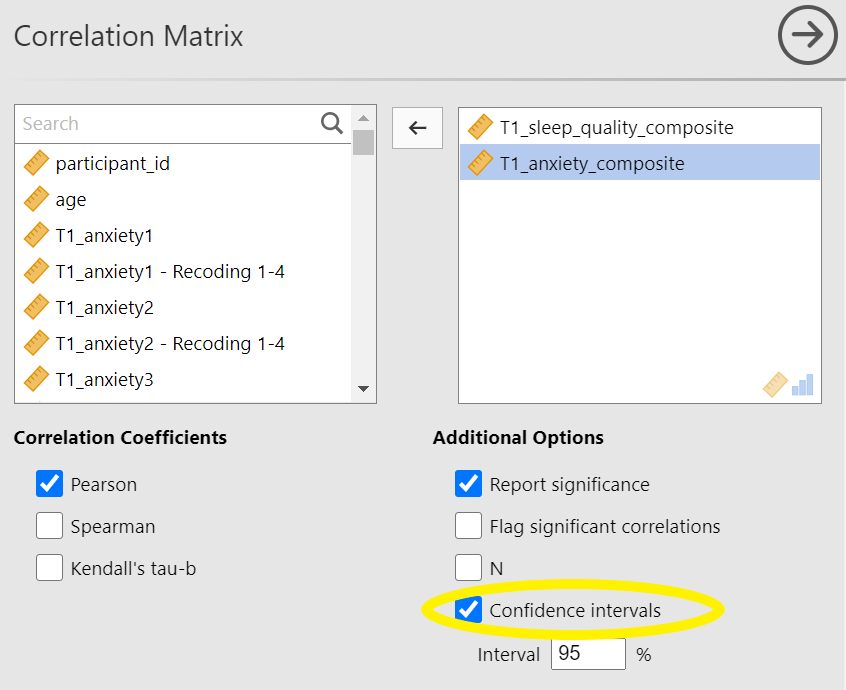
Now, JAMOVI give the confidence intervals for the correlation coefficient, r.
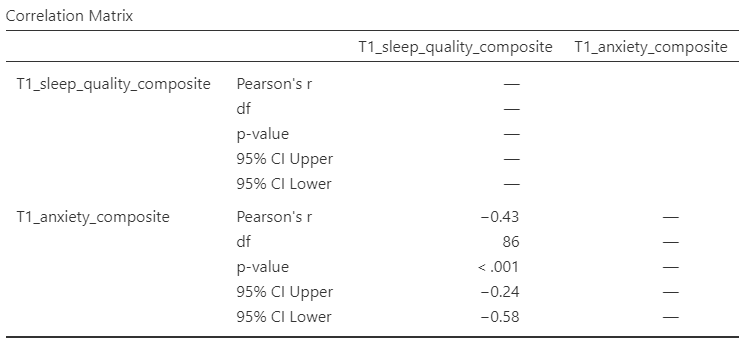
Ask yourself: Why are the degrees of freedom 86 if we have data from 101 participants in the file? Be prepared to offer your thoughts in lab.
You could write the results in APA format as follows:
There was significant correlation between sleep quality and anxiety at the beginning of the term, Pearson’s r(86) = -.43, 95% CI [-.58, -.24], p < .001.
Note that we did not use a leading zero for r and we rounded to two decimal places.
Now consider the example of the correlation between T1_sleep_hours and T1_anxiety_composite:
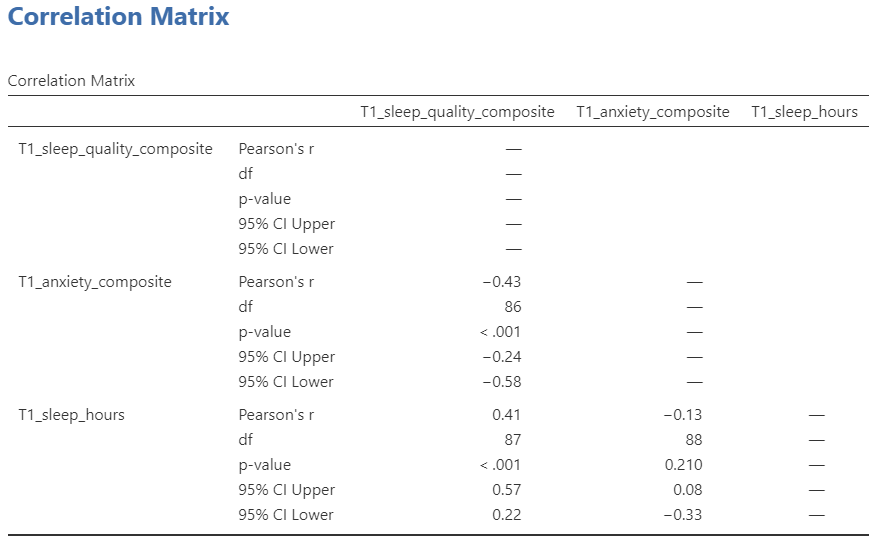
To report this result in APA format, you would write something such as:
There was not a significant correlation between sleep duration and anxiety at the beginning of the term, Pearson’s r(88) = -.13, 95% CI [-.33, .08], p = .210.
6.2.5 Correlation and Scatterplots
To accompany the calculation of the correlation coefficient, the scatterplot is the relevant graph. Depending on your version of JAMOVI, you may have the option to enable a correlation matrix plot from the correlation matrix analysis panel:
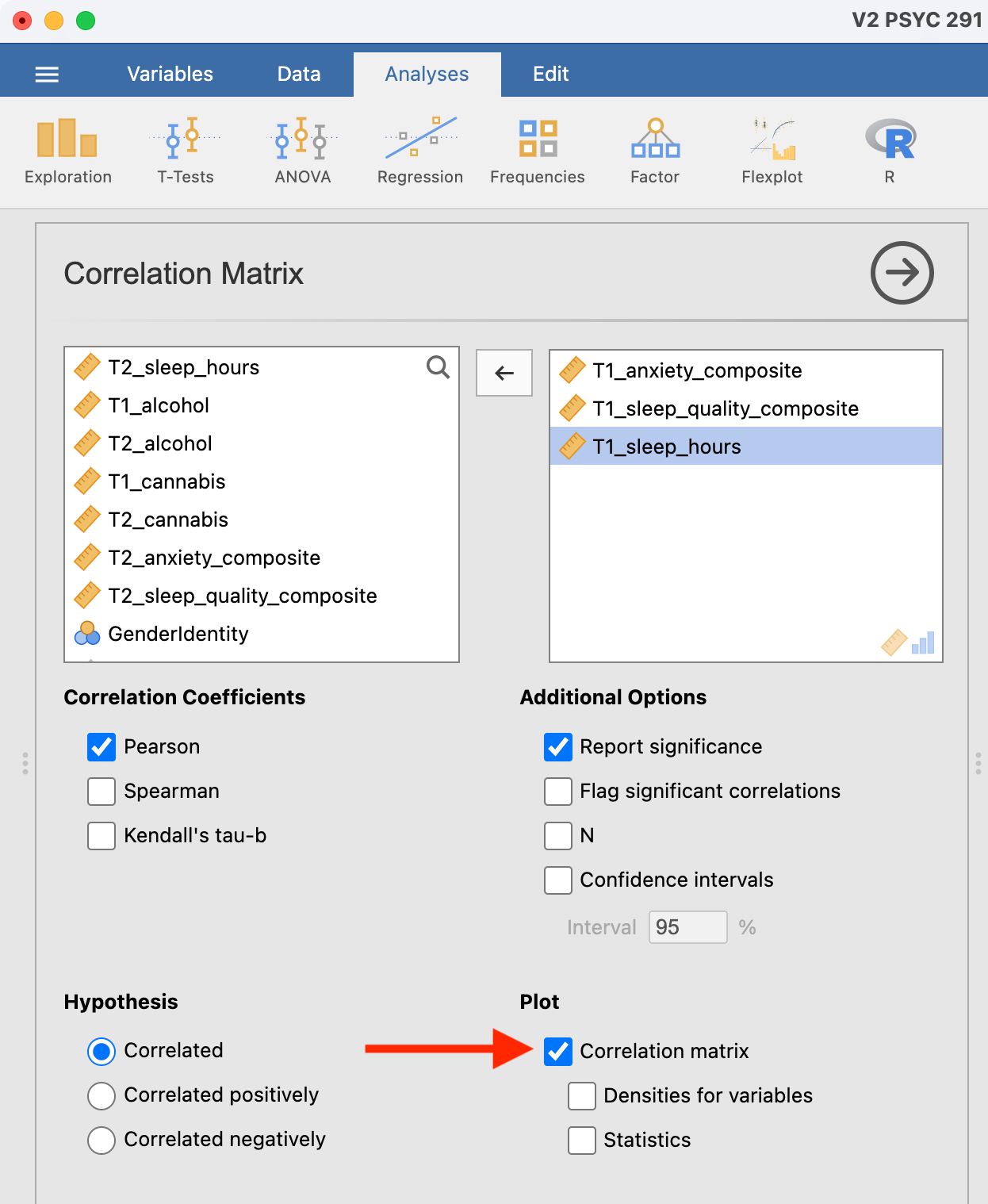
This will produce a scatterplot for each of the correlations you requested.
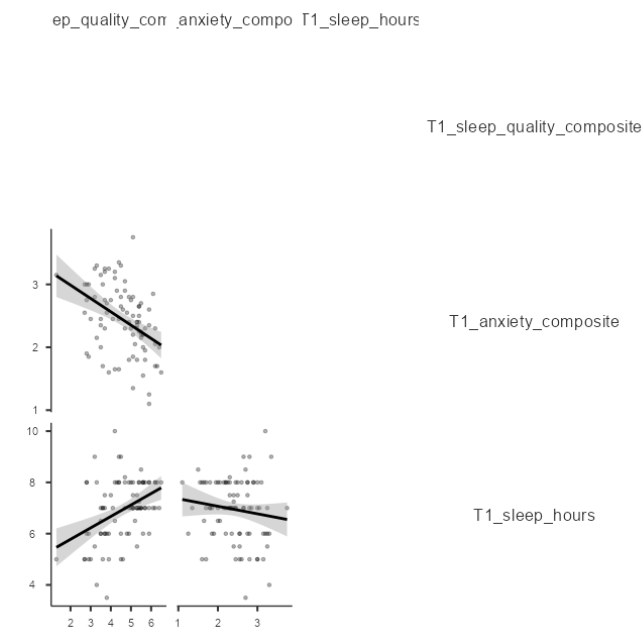
These are handy for having a quick look, but they are kind of small.
6.2.5.1 Adding the Scatterplot module to jamovi
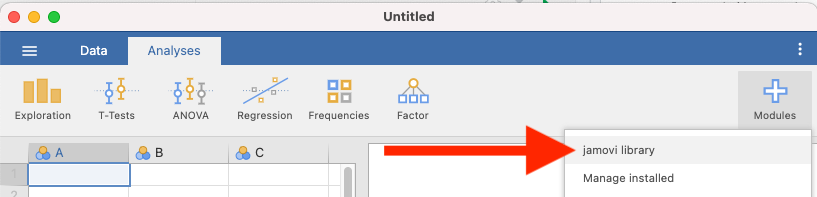
Before you can request a larger scatterplot in jamovi, you must add Scatterplot as a module. To do so, click on the addition sign which is white with a blue trim that has the word “Modules” underneath.

Click jamovi library.
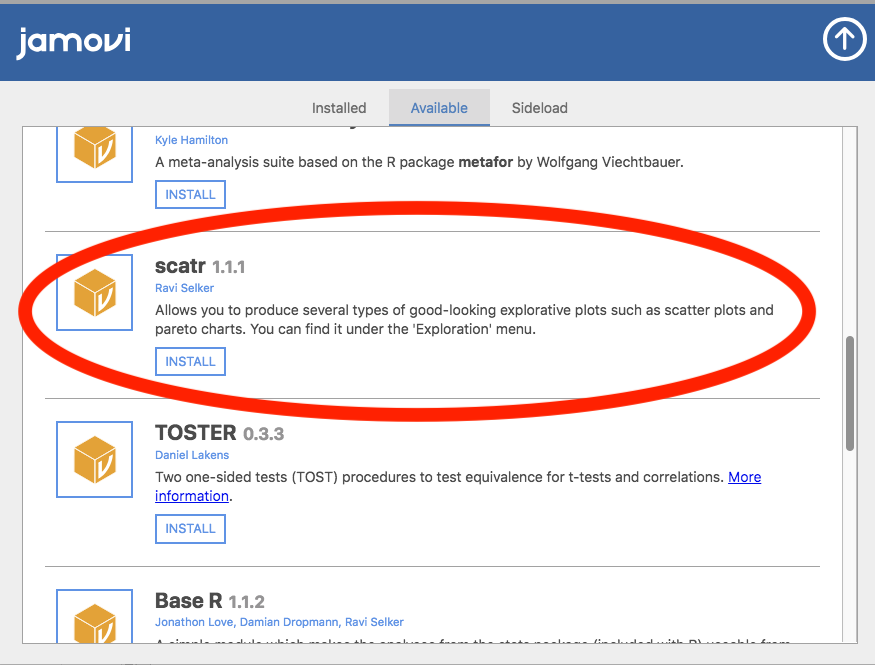
Under the “Available” tab, you should see a module called scatr. Click to INSTALL it.
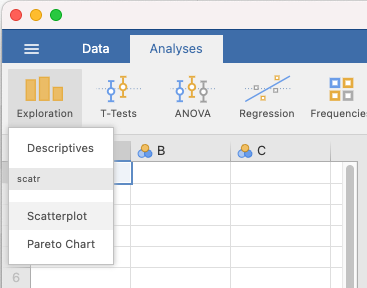
When it is installed, it will appear in your Exploration menu.
6.2.5.2 Getting a visual of the correlation
Let’s continue to create the scatterplot for this data, starting with the T1_sleep_quality_composite and T1_anxiety_composite variables.
Go to Analyses, then Exploration, and then Scatterplot.
Move T1_sleep_quality_composite into the X-Axis box and T1_anxiety_composite into the Y-Axis box:
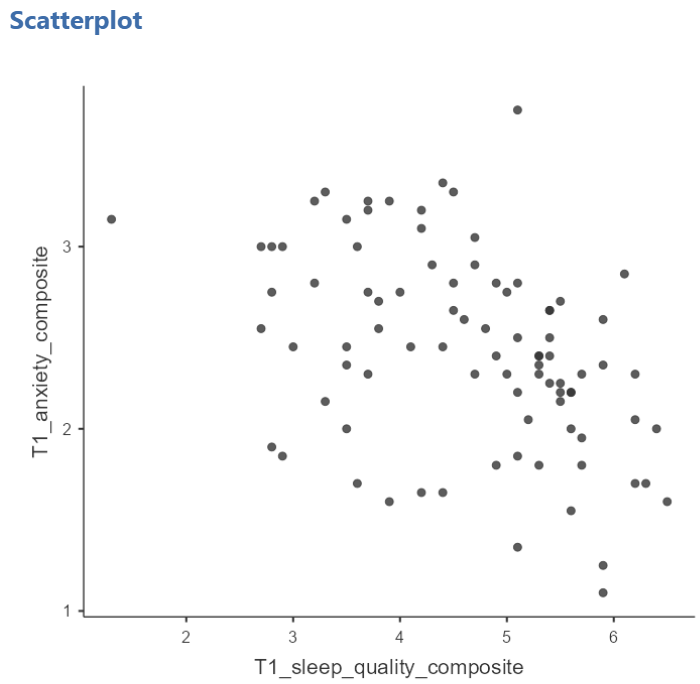
In the Results panel, jamovi will produce a scatterplot of your data, as follows:
At this point, it would be equally correct to plot T1_anxiety_composite on the X-Axis and T1_sleep_quality_composite on the Y-Axis. Note that you get a different graph:
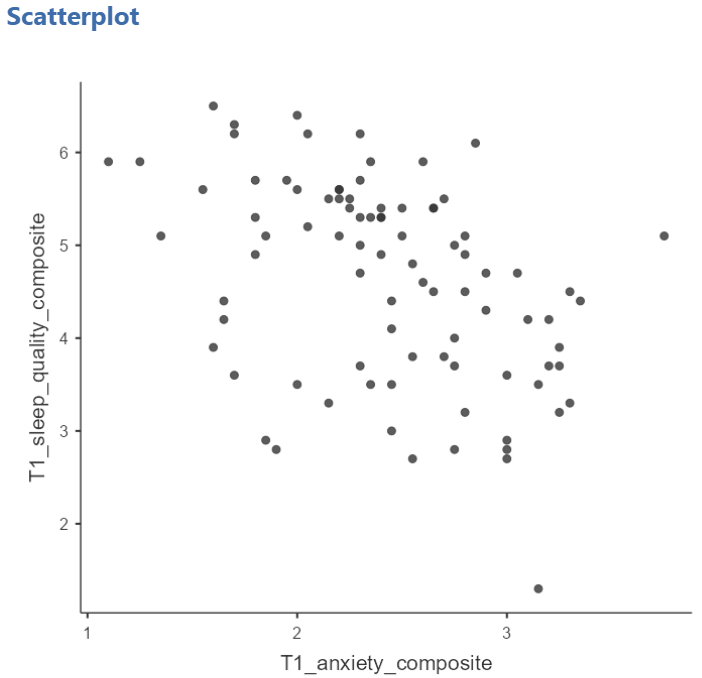
Let’s continue with the second scatterplot, with T1_anxiety_composite on the X-Axis and T1_sleep_quality_composite on the Y-Axis. You can keep this scatterplot as it is, or, you can edit it to include a straight line that best fits the data points. This line is known as the best fit line because it minimizes the distance between the line and the data points. To include the line of best fit, click on Linear under the Regression Line heading.
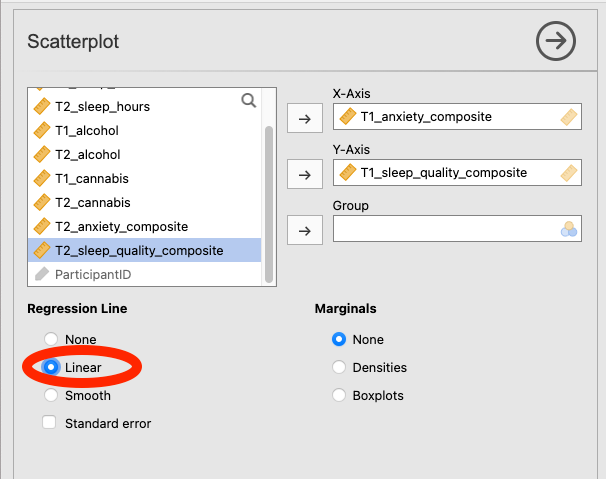
You will find that the graph in your Results panel has now updated and has a line drawn on it.
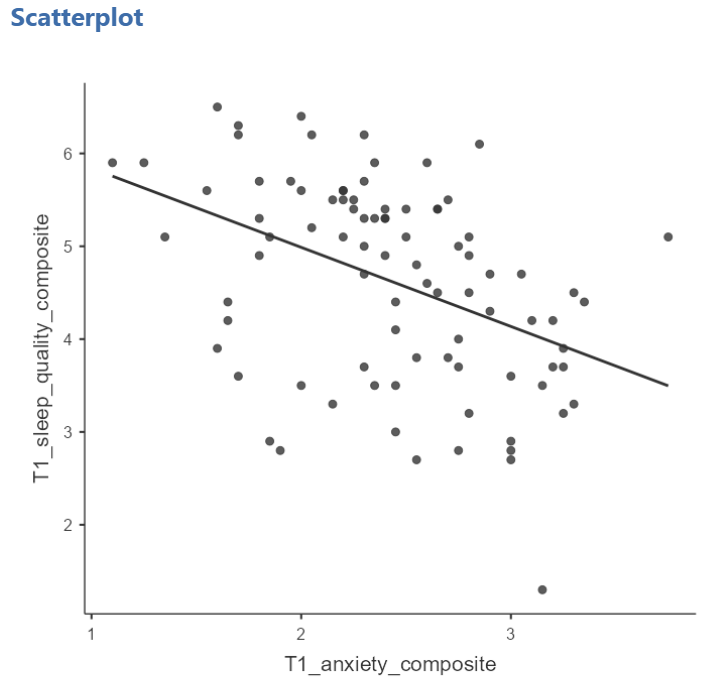
The best fit line goes from the top left to the bottom right; it has a negative slope. This is consistent with the negative Pearson’s r we found in the correlation matrix.
6.2.6 Optional activities
Consider the experiment and dataset from the independent t-test lab. Let’s say you had a different research question: Is the age of the candidate correlated with intellect ratings? You could answer this using correlation. Click Analyses, Regression, and Correlation Matrix.
Then, move age and intellect into the untitled box at the right of the pop-up screeen:
In the Results panel, the output table should look as follows:
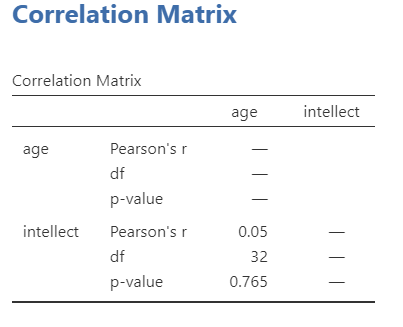
Write a sentence describing the results of this test. Compare your answer to #1 in the “Example answers to practice problems” below.
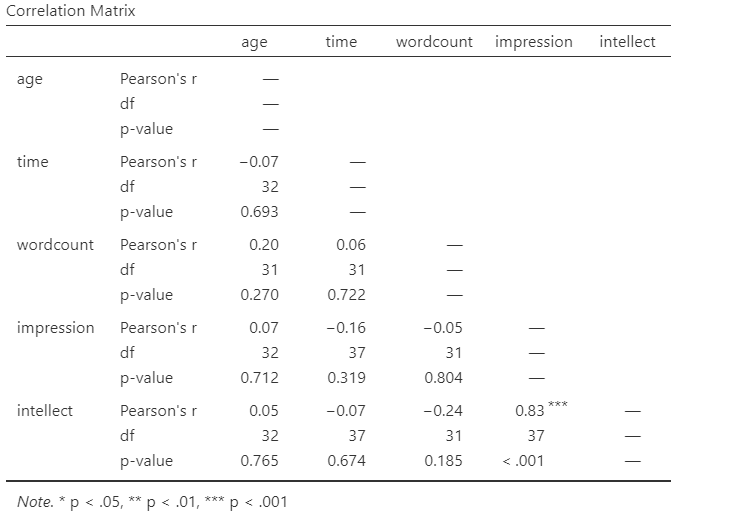
Now, assume you are in the mood to do some exploratory data analysis. We can run multiple bivariate correlations at the same time in the same dialog. Click Analyses, then Regression, and then Correlation Matrix again. To the untitled variables box at the right, add age, time, wordcount, intellect, and impression:
In the Results panel, the output table contains the r- and p-values for each possible pair of the five variables:
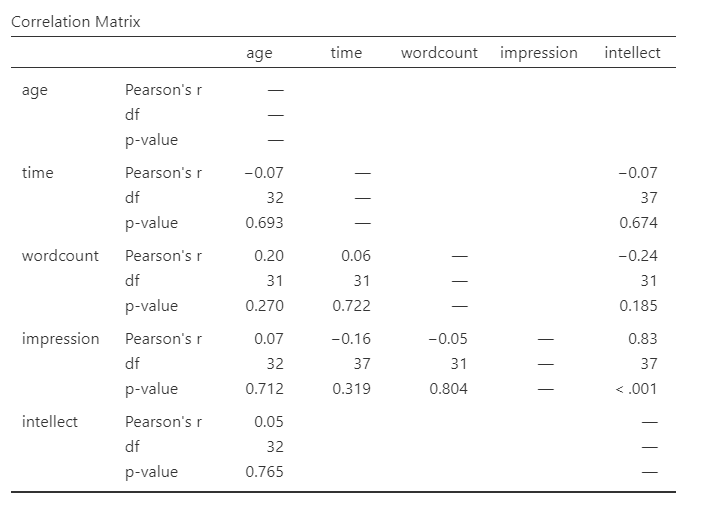
By default, jamovi does not flag significant correlations. Be sure to review the p-values careful and compare them to the alpha level you set. How many significant correlations do you identify in the correlation matrix?
If you would like jamovi to flag significant correlations, you can click Flag significant correlations under “Additional options”.
Under the correlation matrix that appears in the Results panel, you will notice a note. If the p-value is under .05, jamovi will flag the correlation coefficient as * (significant at the .05 level); if the p-value is less than .01, jamovi will flag it as ** (significant at the .01 level); and if the p-value is less than .001, jamovi will flag it as *** (significant at the .001 level).
Let’s pick a few pairs of variables and make scatterplots. We have a good range of different correlations in this table, so we can use these data to practice identifying correlations of different strengths. Click Analyses, Exploration, and then Scatterplot…. Move intellect into the Y-Axis field and age into the X-Axis field.
These commands should produce a scatterplot in the Results panel.
Repeat for all correlations with intellect, using intellect on the y-axis each time to make it easier to compare to the example answers below (#2). Compare the pattern of dots in each scatterplot to the r-values reported in the tables. Can you see the differences between the plots? Can you tell from the scatterplots whether we have violated any of the assumptions of Pearson’s r (i.e., linearity, no outliers)?
6.2.6.1 Applying a Filter
Next, consider the EngageNS Quality of Life dataset. Consider the question: does the number of hours per week a person spends working at their main job correlate with their computer game playing? Use the data data dictionary to identify the relevant variables and run the appropriate correlation.
Next, what if we asked the question: For residents of the Antigonish and Guysborough regions only, does the number of hours per week a person spends working at their main job correlate with their computer game playing? Notice that this question is asking us to find the correlation between the same two variables we used in the previous example, but only in the case where the REGION is equal to 4 (see the data dictionary for an explanation). To achieve this, we’re going to utilize a function called filtering. Filtering the data set makes only those cases that meet our criteria available for use in the analysis to be run. For example, if we filter our data by region and calculate a correlation coefficient, jamovi will find Pearson r for only Antigonish and Guysborough, and not for other regions.
In order to filter the data, we go to the top menu and choose Data and then Filter. In the next window, you must set up the filter; indicate which cases will be used. Under “Filter 1,” click on the formula editor, the fx button. Double click on the variable name (REGION), and it will be incorporated into the filter. Then, use two equal signs, and enter the code for the region of interest (4).
Notice that this will cause a new column in the spreadsheet wherein a green checkmark indicates the case/participant will be included in the analysis and a red “x” indicates the case/participant will be excluded from the analysis.
From here, any analysis you choose to do will be done for only the cases match the filter. Let’s calculate the correlation coefficient, as usual. Click Analyses, then Regression, and then Correlation Matrix.
In the next window, select the variables to be used in the correlation (WORKHR and HM_CGAME).
Notice that in the output now shows a correlation matrix with different results than you saw when you ran the correlation with the entire data set.
Again, you may want to inspect the scatterplot to get a visual representation of this correlation coefficient for the data collected from participants in the Antigonish-Guysborough region. Challenge: Give the creation of this scatterplot a try on your own.
6.2.6.2 Removing the Filter
It is very important to remember that once you have applied a filter, every analysis will be done on the split variable. If you want to go back to performing analyses and calculating statistics for the data as a whole, you must delete the filter. To do this, you can highlight the column showing the filter in the spreadsheet, go to Data, and then Delete. You will be prompted with a question to verify that you want to delete the filter. Click Yes.
6.2.7 Example answers to optional activities
Intellect ratings were not significantly correlated with the age of the candidates, r = .05, p > .05.
You should have created four scatterplots. They are included below as well as some notes about each.

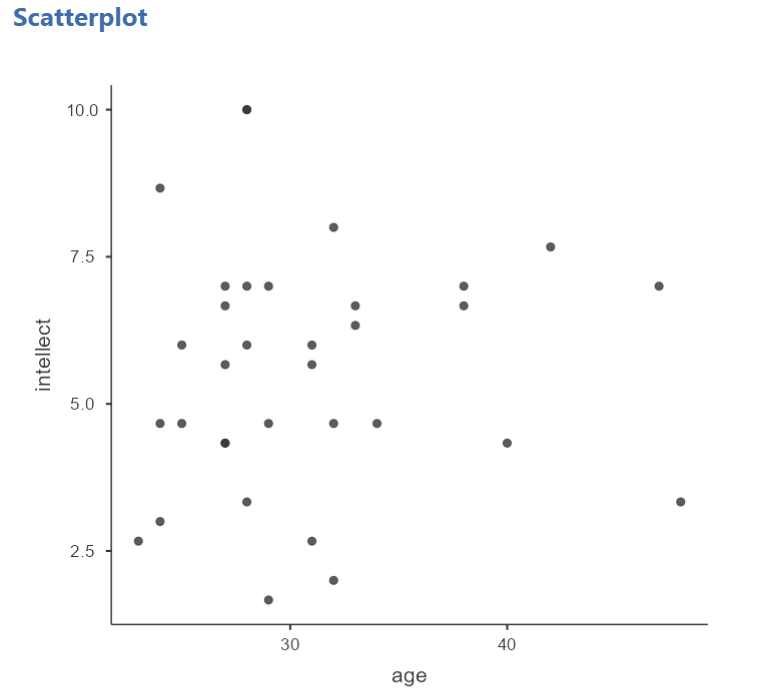
For the correlation between age and intellect, we found r was very close to 0, at .05. This is reflected in the pattern of dots, which are spread fairly uniformly across the entire plot. There are no concerns with violating the assumption of linearity on this plot. There are also no outliers.

For the correlation between time and intellect, we found r was also close to 0 but negative, at -.07. It is harder to link the r with the plot in this case because of the two dots far to the right in the plot. These might be outliers and could be investigated further, but how to do so is not covered in PSYC 292.

The correlation between wordcount and intellect was r = -.24. This is a fairly weak correlation. The dot to the far right in the first plot might be an outlier and could be investigated further, but how to do so is not covered in PSYC 292. If you focus on the cluster of dots on the left, you can get the impression that there are more dots in the top left and bottom right than the other two quadrants. This is more obvious if we zoom in:
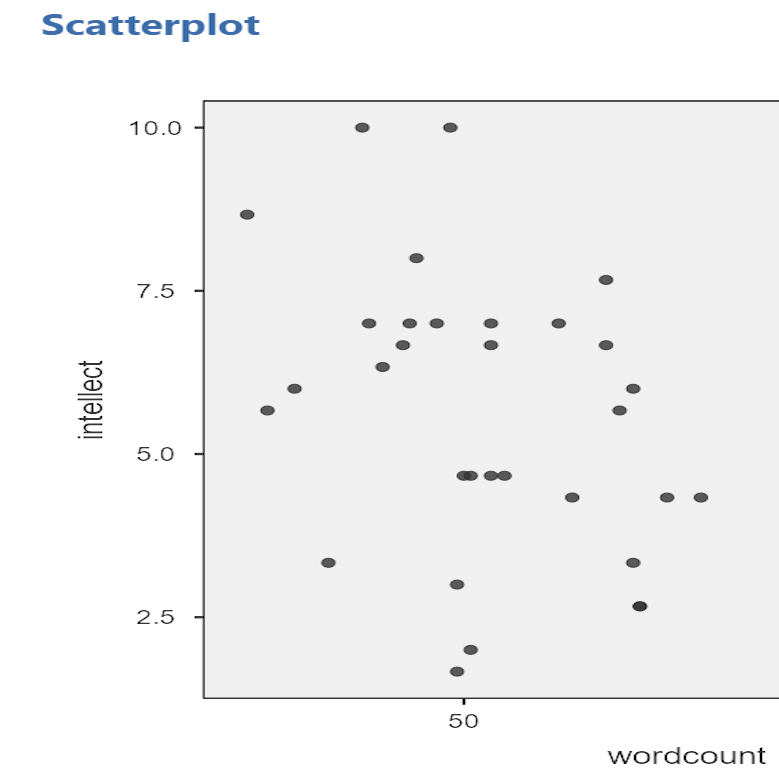
Next, let’s look at the scatterplot for impression and intellect.

For impression and intellect, a correlation of r = .83 was observed. In the scatterplot, you can see the dots cluster around an imaginary line that goes from the bottom left corner to the top left corner. There are no concerns that the assumption of linearity has been violated. There is also no evidence of outliers.
6.2.8 Homework
See Moodle.
6.2.9 Practice Problems
Use the EngageNS Quality of Life dataset to answer questions 1-6.
Construct a scatterplot using R_FRIENDS on the x-axis and SOC_FRND on the y-axis to depict the results you found for the last homework question.
Can you run a Pearson’s correlation analysis on the following pairs of variables? Why or why not?
- SEX and SLEEP?
- COMP_TIME and SLEEP?
- MAINACT and EDUCAT?
- Run the correlation analysis for any set(s) of variables you determined to be appropriate for using Pearson’s correlation. Report the correlation coefficient. Is it considered statistically significant? Write your results following the APA rules discussed below.
Some formatting guidelines for writing results sections:
Note the name of the test you performed (in this case, Pearson’s correlation) and whether the result is significant or non-significant (Note: We do not use the word insignificant.).
We usually round to two decimal places, except for p-values. If your p-value was .0001, it would be okay to write p = .0001 or p < .001.
Do not include a leading 0 before the decimal for the p-value (p = .001 not p = 0.001, or p < .05 not p < 0.05) or for correlation coefficients, r (for example, r = .56).
Yes, I’m serious. No, I don’t know why. Yes, it does seem a bit silly. Yes, you lose points if you don’t adhere to APA format when requested to do so.
Pay attention to spaces, parentheses, etc. APA is very picky about that. For example, it’s t(33.4) = -3.48 not t(33.4)=-3.48. There are spaces on either side of =, >, or < symbols.
Italicize symbols such as M, SD, p, and r.
Construct the scatterplot for any set(s) of variables you determined to be appropriate for using Pearson’s correlation. What do you notice about the scatterplot? Does the slope increase or decrease? Do the dots closely follow the line of best fit?
Consider participants’ reported number of close friends and their reported time spent socializing with friends. Are these scores correlated? If so, report r and whether the correlation is significant or non-significant.
Apply a filter so that you are looking at only the data for participants’ whose main activity is going to school (Hint: Use the data dictionary to figure out how participants’ main activities were coded). Now, run the same correlation you looked at in #1. Are number of close friends and reported time spent socializing with friends correlated for students? Is the correlation significant? Compare these results to the results in #1. Is the correlation between number of close friends and reported time spent socializing with friends stronger or weaker for students than it is for Nova Scotians?
The following three questions are copied verbatim from Answering questions with data: The lab manual for R, Excel, SPSS and JAMOVI, Lab 3, Section 3.2.4, SPSS, according to its CC license. Thank you to Crump, Krishnan, Volz, & Chavarga (2018).
Imagine a researcher found a positive correlation between two variables, and reported that the r value was +.3. One possibility is that there is a true correlation between these two variables. Discuss one alternative possibility that would also explain the observation of +.3 value between the variables.
Explain the difference between a correlation of r = .3 and r = .7. What does a larger value of r represent?
Explain the difference between a correlation of r = .5, and r = -.5.
6.3 JAMOVI – Correlation – FOR PSYC 394 STUDENTS
Some of this section is copied almost verbatim, with some editorial changes, from Answering questions with data: The lab manual for R, Excel, SPSS and JAMOVI, Lab 3, Section 3.4, SPSS, according to its CC license. Thank you to Crump, Krishnan, Volz, & Chavarga (2018).
In this lab, we will use JAMOVI to calculate the correlation coefficient. We will focus on the most commonly used Pearson’s coefficient, r. We will learn how to:
- Calculate the Pearson’s r correlation coefficient for bivariate data
- Produce a correlation matrix, reporting Pearson’s r for more than two variables at a time
- Produce a scatterplot
6.3.1 Pre-lab reading and tasks
6.3.1.1 Assumptions of correlation
This lab will focus on Pearson’s correlation. For the calculation to make sense, the data must meet certain criteria. These are known as the assumptions of Pearson’s correlation.
Pearson’s correlation assumes:
There is a linear relation between the two variables. To assess this, the scale of measurement of both variables must be at least interval. You cannot assess whether the relation is linear without equal spacing between intervals. Do not run Pearson’s correlation on nominal or ordinal variables.
There are no outliers. We are not going to look deeply into outliers during this lab. If you have a point in your dataset that is quite far away from the other points, you might have an outlier.
This third assumption is paraphrased from Field, A (2018) Discovering Statistics Using IMB SPSS Statistics, 5th edition. Sage: California. This is a copyrighted textbook.
- Additionally, the data must adhere to the normality assumption. Recall the central limit theorem. If your sample size is large, you don’t need to worry about normality. If your sample size is small, you should check that your variables are normally distributed.
You do not need to check the assumptions before lab.
6.3.1.2 Download and open data
For the purpose of the lab demonstration, we will work with a data set provided by Dolan, Oort, Stoel, and Wicherts (2009) in their investigation of measurement invariance. These data were collected from 500 psychology students at University of Amsterdam on the Big Five personality dimensions [Neuroticism (N), Extraversion (E), Openness to experience (O), Agreeableness (A), and Conscientiousness (C)] using the NEO-PI-R test . You can download the data here.
Have the file open in JAMOVI before the beginning of your lab session.
6.3.1.3 Install scatr module if required
As you read through this section on using JAMOVI to conduct correlations, you will see the need for the scatr module. The scatr module may be installed on your version of JAMOVI by default. If so, you should see it loaded under the Analyses ->and Exploration -> menus:
If you do not see this module on your version of JAMOVI, before lab, please download and install it using the add-on Modules icon (the plus sign at the top right) and JAMOVI library; due to the short duration of our labs, we will not have time during lab to wait for downloading and installation.
6.3.2 Correlation Coefficient for Bivariate Data
Bivariate is a fancy way of saying two variables. Let’s say you were interested in the relationship between two variables: Neuroticism and Conscientiousness. To calculate a correlation in JAMOVI, go to Analyses -> Regression -> Correlation Matrix:
Move your variables of interest, Neuroticism and Conscientiousness, to the window on the right of the commands pane:
An output table will be generated in the results panel:

The table indicates that Pearson’s r between the two variables is -0.37, with a p-value of less than .0001. This is a negative correlation: as the scores on one variable increase, the scores on the other variable decrease.
Notice the number of other options you might select in the commands pane. You could select Spearman or Kendall’s tau-b correlations. These tests can be useful if the data are measured on an ordinal scale or if there are outliers. Also, notice the options to request that JAMOVI flag significant correlations and to request the 95% confidence intervals. By default, the hypothesis is set as Correlated (a two-tailed hypothesis). You might change the default setting by selecting Correlated positively or Correlated negatively (both one-tailed hypotheses).
6.3.3 Correlation Matrix
If you have more than two variables in your spreadsheet and would like to evaluate correlations between several variables taken two at a time, you can enter multiple variables into the correlation window and obtain a correlation matrix. The correlation matrix is a table showing every possible bivariate correlation amongst a group of variables.
Let’s add all five variables to our correlation matrix. First, move the variable to the right box:
Now the output panel has 10 sets of results:
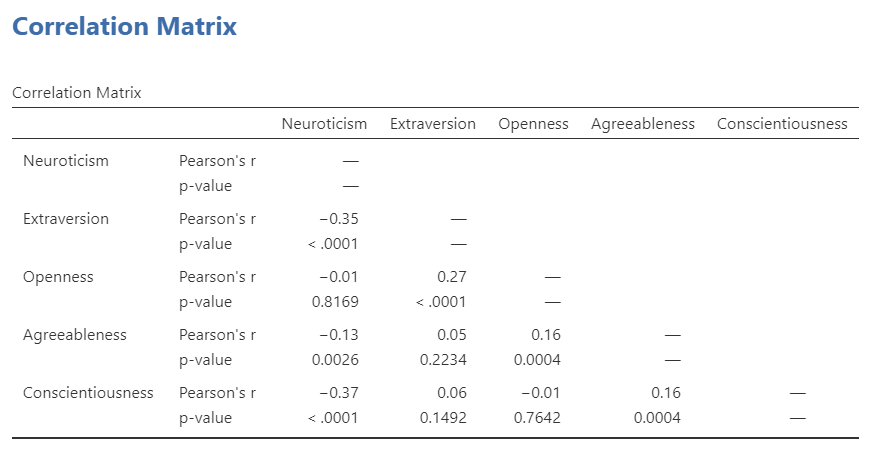
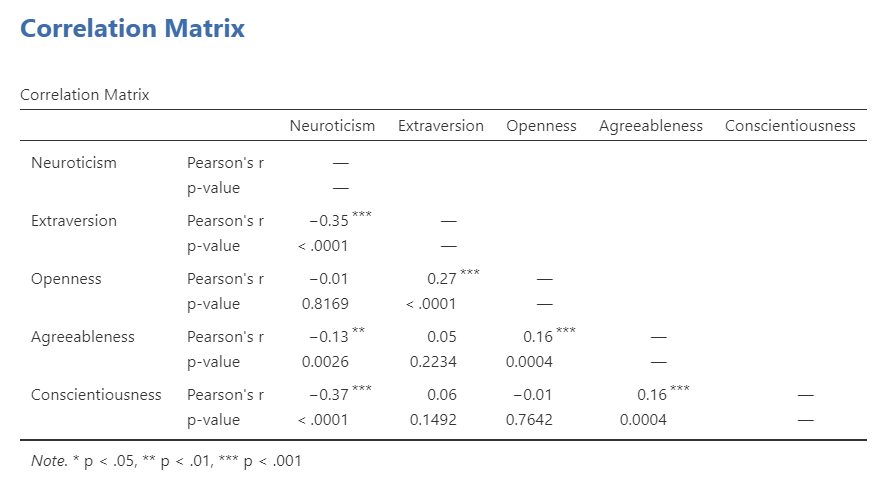
Note that some of the correlations are negative, and some are positive. Some are significant (with p < .05), and some are not.
If we request that JAMOVI flag the significant correlations, asterisks (*) will be used to show the significance levels against three commonly used alpha levels (One asterisk denotes p < .05, two asterisks denote p < .01, and three asterisks denote p < .001.)
6.3.4 APA format reporting of a correlation
Recall the output for the correlation between Neuroticism and Conscientiousness:
You could write the results in APA format as follows:
A significant correlation was found between Neuroticism and Conscientiousness, Pearson’s r = -.37, p < .0001.
Note that we did not use a leading zero for r and we rounded to two decimal places.
Now consider the example of the correlation between Neuroticism and Openness:
To report this result in APA format, you would write something such as:
There was not a significant correlation between Neuroticism and Openness, Pearson’s r = -.01, p > .05.
Some formatting guidelines for writing results sections:
Indicate the name of the test you performed (in this case, Pearson’s correlation) and whether the result is significant or non-significant (Note: We do not use the word insignificant.).
We usually round to two decimal places, except for p-values. If your p-value was .0001, it would be okay to write p = .0001 or p < .001.
Do not include a leading 0 before the decimal for the p-value (p = .001 not p = 0.001, or p < .05 not p < 0.05) or for correlation coefficients, r (for example, r = .56).
Yes, I’m serious. No, I don’t know why. Yes, it does seem a bit silly. Yes, you lose points if you don’t adhere to APA format when requested to do so.
Pay attention to spaces, parentheses, etc. APA is very picky about that. For example, it’s t(33.4) = -3.48 not t(33.4)=-3.48. There are spaces on either side of =, >, or < symbols.
Italicize symbols such as M, SD, p, and r.
6.3.5 Correlation and Scatterplots
To accompany the calculation of the correlation coefficient, the scatterplot is the relevant graph. Depending on your version of JAMOVI, you may have the option to enable a correlation matrix plot from the correlation matrix commands panel. Let’s return to the first correlational analysis with only two variables, Neuroticism and Conscientiousness. Highlight those results in your Results pane, and click to add Correlation matrix under the “Plot.”
This will produce a scatterplot for the correlations.
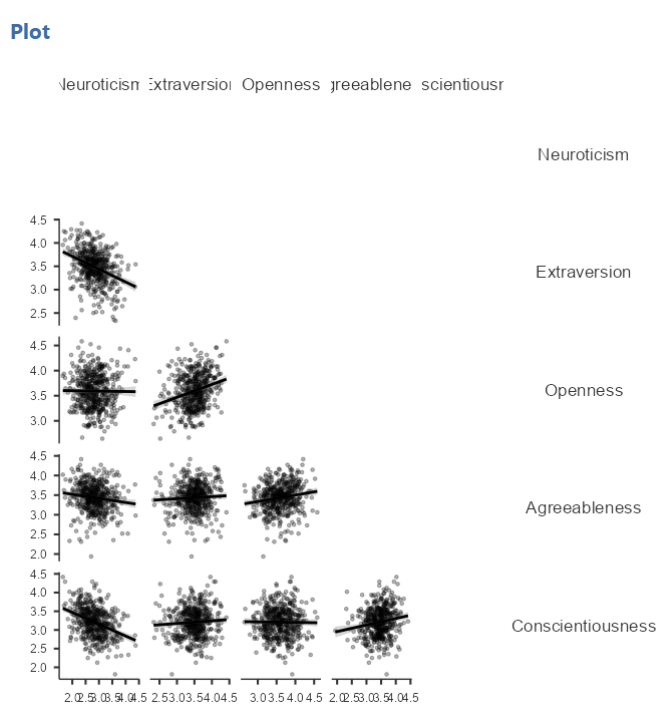
These plots are handy for having a quick look, but are relatively small. Furthermore, when there are a number of correlations requested, the labels or axes values may start to overlap resulting in a graph that is not easy to read. Consider this result generated when the plot is requested in the correlational analysis involving all five variables:
This will produce a scatterplot for the correlations.
6.3.5.1 Getting a visual of the correlation
Let’s continue to create the scatterplot for this data, starting with the Neuroticism and Conscientiousness variables.
Go to Analyses, then Exploration, and then Scatterplot.
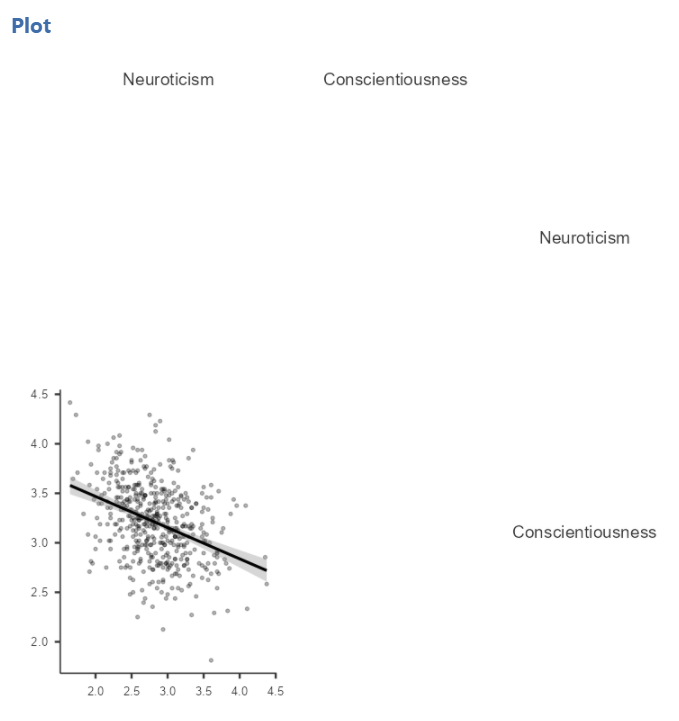
Move Neuroticism into the X-Axis box and Conscientiousness into the Y-Axis box.
In the Results panel, JAMOVI will produce a scatterplot of your data, as follows:
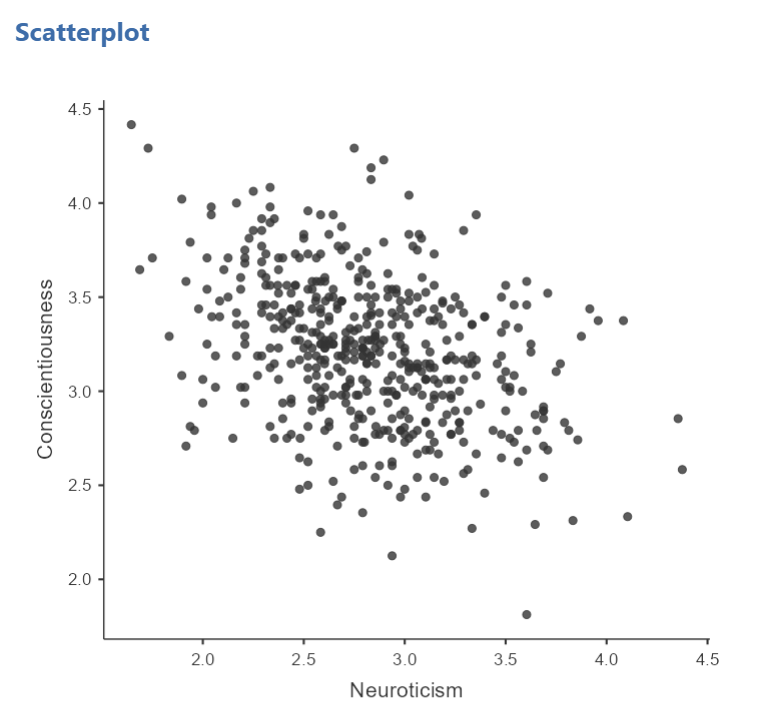
At this point, it would be equally correct to plot Conscientiousness on the x-axis and Neuroticism on the y-axis. Note that you get a different graph:
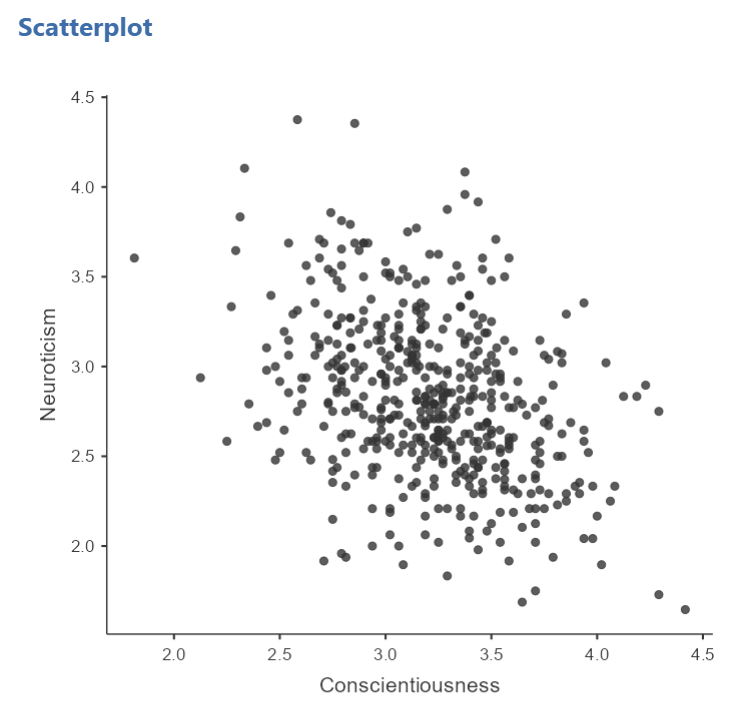
Let’s continue with the second scatterplot, with Conscientiousness on the x-axis and Neuroticism on the y-axis. You might keep this graph as it is, or you may choose to include a line through it. To add the line, select Linear under Regression Line. This line is known as the best fit line (or the line of best fit) because it minimizes the distance between the line and the data points.
You will find that the graph in your Results panel has now updated and has a line drawn on it.
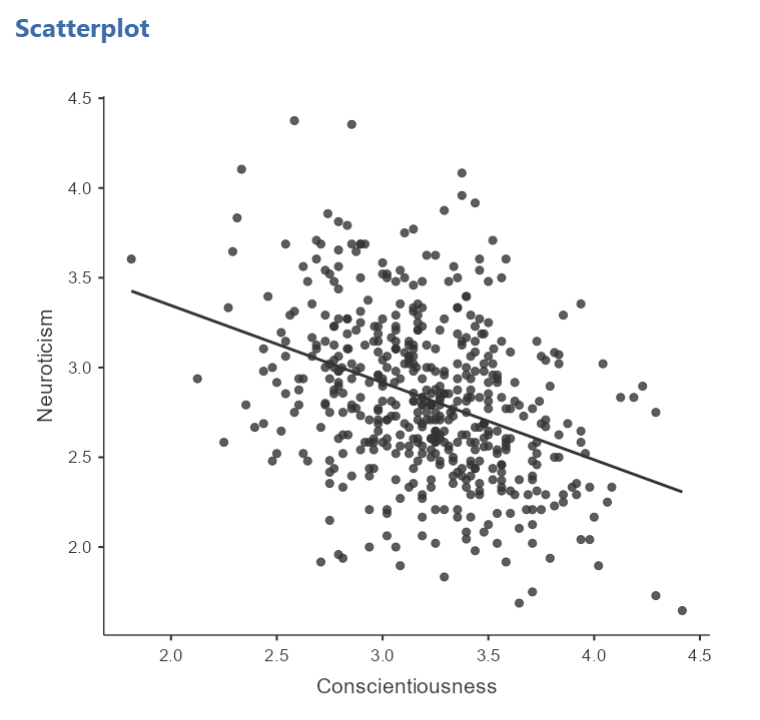
This best fit line goes from the upper top left to the bottom right; it has a negative slope. This is consistent with the negative Pearson’s r we found in the correlation matrix.
6.3.6 Optional activities
Consider a dataset from Schroeder and Epley (2005). Rather than asking about a difference in how candidates were perceived by recruiters as the authors did, imagine you had a different research question: Is the age of the candidate correlated with intellect ratings? You could answer this using correlation. Click Analyses, Regression, and Correlation Matrix.

Then, move age and intellect into the untitled box at the right of the pop-up screen:

In the Results panel, the output table should look as follows:

Write a sentence describing the results of this test. Compare your answer to #1 in the “Example answers to practice problems” below.
Now, assume you are in the mood to do some exploratory data analysis. We can run multiple bivariate correlations at the same time in the same dialog. Click Analyses, then Regression, and then Correlation Matrix again. To the untitled variables box at the right, add age, time, wordcount, intellect, and impression:

In the Results panel, the output table contains the r- and p-values for each possible pair of the five variables:

By default, JAMOVI does not flag significant correlations. Be sure to review the p-values careful and compare them to the alpha level you set. How many significant correlations do you identify in the correlation matrix?
If you would like JAMOVI to flag significant correlations, you can click Flag significant correlations under “Additional options”.

As aforementioned, under the correlation matrix that appears in the Results panel, you will notice a note. If the p-value is under .05, JAMOVI will flag the correlation coefficient as * (significant at the .05 level); if the p-value is less than .01, JAMOVI will flag it as ** (significant at the .01 level); and if the p-value is less than .001, JAMOVI will flag it as *** (significant at the .001 level).

Let’s pick a few pairs of variables and make scatterplots. We have a good range of different correlations in this table, so we can use these data to practice identifying correlations of different strengths. Click Analyses, Exploration, and then Scatterplot…. Move intellect into the Y-Axis field and age into the X-Axis field.

These commands should produce a scatterplot in the Results panel.
Repeat for all correlations with intellect, using intellect on the y-axis each time to make it easier to compare to the example answers below (#2). Compare the pattern of dots in each scatterplot to the r-values reported in the tables. Can you see the differences between the plots? Can you tell from the scatterplots whether we have violated any of the assumptions of Pearson’s r (i.e., linearity, no outliers)?
6.3.7 Example answers to optional activities
Intellect ratings were not significantly correlated with the age of the candidates, r = .05, p > .05.
You should have created four scatterplots. They are included below as well as some notes about each.
For the correlation between age and intellect, we found r was very close to 0, at .05. This is reflected in the pattern of dots, which are spread fairly uniformly across the entire plot. There are no concerns with violating the assumption of linearity on this plot. There are also no outliers.
For the correlation between time and intellect, we found r was also close to 0 but negative, at -.07. It is harder to link the r with the plot in this case because of the two dots far to the right in the plot. These might be outliers and could be investigated further. (Challenge yourself: Can you identify those cases that create the two dots off to the left? Are they outliers? How do you know? How would you deal with them if they are outliers? Why?)
The correlation between wordcount and intellect was r = -.24. This is a fairly weak correlation. The dot to the far right in the first plot might be an outlier and could be investigated further. (Challenge yourself: Can you identify those cases that create the two dots off to the left? Are they outliers? How do you know? How would you deal with them if they are outliers? Why?) If you focus on the cluster of dots on the left, you can get the impression that there are more dots in the top left and bottom right than the other two quadrants. This is more obvious if we zoom in:
Next, let’s look at the scatterplot for impression and intellect.
For impression and intellect, a correlation of r = .83 was observed. In the scatterplot, you can see the dots cluster around an imaginary line that goes from the bottom left corner to the top left corner. There are no concerns that the assumption of linearity has been violated. There is also no evidence of outliers.
6.3.8 Homework
See Moodle.
6.3.9 Practice Problems
- Check the data set used in the lab demonstration to see if it meets the assumptions of Pearson’s correlation. If not, indicate how you might “clean” the data. Justify your answer.
The following three questions are copied verbatim from Answering questions with data: The lab manual for R, Excel, SPSS and JAMOVI, Lab 3, Section 3.2.4, SPSS, according to its CC license. Thank you to Crump, Krishnan, Volz, & Chavarga (2018).
Imagine a researcher found a positive correlation between two variables, and reported that the r value was +.3. One possibility is that there is a true correlation between these two variables. Discuss one alternative possibility that would also explain the observation of +.3 value between the variables.
Explain the difference between a correlation of r = .3 and r = .7. What does a larger value of r represent?
Explain the difference between a correlation of r = .5, and r = -.5.