
Chapter 8 Lab 8 Repeated Measures ANOVA
However, perhaps the main point is that you are under no obligation to analyse variance into its parts if it does not come apart easily, and its unwillingness to do so naturally indicates that one’s line of approach is not very fruitful. —R. A. Fisher
8.1 Betcha can’t type JHDBZKCO very fast on your first try
This lab activity uses the data from Behmer & Crump (2017) to teach one-factor repeated measures ANOVA with-up follow comparisons
8.1.1 STUDY DESCRIPTION
Behmer & Crump (2017) used the everyday task of typing on a computer keyboard to ask questions about how people learn to put sequences of actions together. Whenever you type a series of letters on the keyboard, you are putting a sequence of actions together, so typing is task that could be used to measure skilled sequencing. Typing also happens to be a convenient task for measuring sequencing. For example, every time a person types a letter, the timing of the button press and the letter pressed can be measured and stored for later analysis.
Behmer & Crump were interested in asking a few different questions, however, we will simplify everything and talk about replication. First we describe an interesting finding from previous research. Behmer & Crump repeated an experiment that should also produce this same finding. If they succeed in doing this, it means the finding can be replicated, and that it happens in more than one lab.
Finding from previous resaearch: Prior research showed that typists do something funny. Skilled typists can type normal words very fast. This suggests they know how to locate all of the letters on the keyboard, and can press each letter very quickly to type words. That part isn’t particularly funny. However, if you take really skilled typists and make them type random letters like this: kwitb dhhgjtryq xkldpt mazhyffdt, guess what happens? They slow down a lot. It’s kind of weird that a typist would slow down, after all they can type letters really fast when they appear in words, but not when they appear in random orders…what gives? Last, it turns out that typists are kind of in the middle in terms of speed, if you ask them to type non-words that have similar properties to words, such as: quenp hamlke phwempy.
To summarize, prior research showed that typing speed changes as a function of the structure of the text, roughly in this order from fastest to slowest.
(FASTEST) Normal Words < Word-like Non-words < Random strings (SLOWEST)
Replication question: Behmer & Crump also measured typists while they typed words, non-words that were English-like, and random strings. They had some additional things they were interested in, but for us, we are interested in whether they would show the same effect. Would they replicate the pattern: Normal words (Fastest) < Word-like Non-words (medium) <- Random strings (Slowest)?
8.1.2 Study Methods
The authors conducted a repeated measures experiment. A total of 38 subjects were used for the analysis.
Independent Variable: The IV Stimulus or typing material had three levels: Normal, Bigrams, and Random. Normal refers to normal 5 letter English words (like truck, or plant). Bigrams refers to non-words that have properties similar to words (e.g., phemt quilp). Random refers to 5 letter strings whose letters were totally random (qmklt gdrzn lprni).
Dependent Variables: There were three dependent variables, that all measured different aspects of typing performance. Reaction times (RTs) were defined as the temporal interval between seeing a stimulus (to type), and then starting to type it (first key press). Inter-keystroke intervals (IKSIs) are the times between each key-press. Last, accuracy was also measured (correct or incorrect key-presses)
The task: Participants (who happened to also be students from Brooklyn College) sat in front a computer. They were presented with one stimulus (word, bigrams, or random) at a time. As soon as they saw the string of letters, they typed it as quickly and accurately as they could, then they moved on to the next trial.
Reminder, this is a repeated measures design because each participant typed letter strings from the word, bigrams, and random conditions.
8.2 Lab Skills Learned
- Conducting a one-factor repeated measures ANOVA
- Conducting follow-up comparisons
8.3 Important Stuff
- citation: Behmer, Lawrence P., Crump, M. J. C. (2017). Spatial Knowledge during Skilled Action Sequencing: Hierarchical versus Non-Hierarchical Representations. Attention, Perception & Psychophysics, 79, 2435-2448.
- Link to .pdf of article
- Data in .csv format
8.4 R
8.4.1 Load the data
Remember that any line with a # makes a comment and the code does not run. Below is how to load the .csv data from the online repository, or from a local file (you need to change the file path to where the local file is, if you downloaded it). The data contains all of the measures and conditions from Experiment 1 in the paper.
8.4.2 Inspect the dataframe
This will give you a big picture of the data frame. Click the button to view it in your browser, then take a look to see what is in it.
Note, there is some weird stuff in code above. Normally, we would just write view(dfSummary(all_data)), why we add this: all_data[,c(1:7,10:20)]? It turns out the dfSummary function didn’t like some of the data. In particular it didn’t like the data in columns 8 an 9 (notice those numbers are missing, the range inside c is 1 to 7 and 10 to 20). It doesn’t mean the data isn’t there, just that it didn’t want to display it in the viewer.
8.4.3 Get the data you need
This data file contains all of the data from Experiment 1 in the paper. So, we don’t need to get rid of any rows.
There are numerous columns, some of them we don’t need for the analysis. But, we’ll just ignore these later when we use dplyr to group by the columns we want.
The structure of this data a file is in long form. Every row described a measurement for a single key-press. For example, the first 5 rows, have data for the timing of the first 5 key-presses, that the first subject made to type the first string of letters they saw. In total there were 85,410 key-presses made. That’s quite a lot.
8.4.3.1 The independent variable
The important independent variable is in the column Stimulus.
- Normal (5 letter English words)
- Bigrams (5 letter strings that kind of looked like words)
- Random (5 letter strings that were random)
It is also important to know that the Order column codes the position for each letter, from 1 to 5.
Note: there was another independent variable in the study as well. We talk about this later. The second IV is coded in the Block column.
- Baseline (normal typing, keyboard is visible while typing)
- Manipulation (occluded typing, keyboard is covered while typing)
8.4.3.2 The dependent variables
TimeFromOnset: This column records the temporal interval in milliseconds between the onset of the word and each key-press. When order is 1 (first keystroke), the number here is the reaction time to start typing.PureRTs: This column contains keystroke intervals. The first interval is between the onset of the word and the first key-press (order 1), the second interval is between the first and second key-press (order 2), and so on.PureRTsfor orders 2 to 5, represent the inter-keystroke intervals reported in paper.AllCorrect: 0 means incorrect (wrong letter was typed), 1 means correct (correct letter was typed)
8.4.4 Look at the data
Remember before we do any analysis, we always want to “look” at the data. This first pass let’s us know if the data “look right”. For example, the data file could be messed up and maybe there aren’t any numbers there, or maybe the numbers are just too weird.
For example, this study involves reaction times: the time between seeing something and responding to it. If you had done a study like this before, you would know that it usually doesn’t take people that long to start responding. Most reaction times will be under a second (or 1000 milliseconds). But, sometime people are little slow, and sometimes they do funny things like check their phone in the middle of an experiment.
Before I analyze reaction time data, I often make a histogram of all of the RT data, like this:
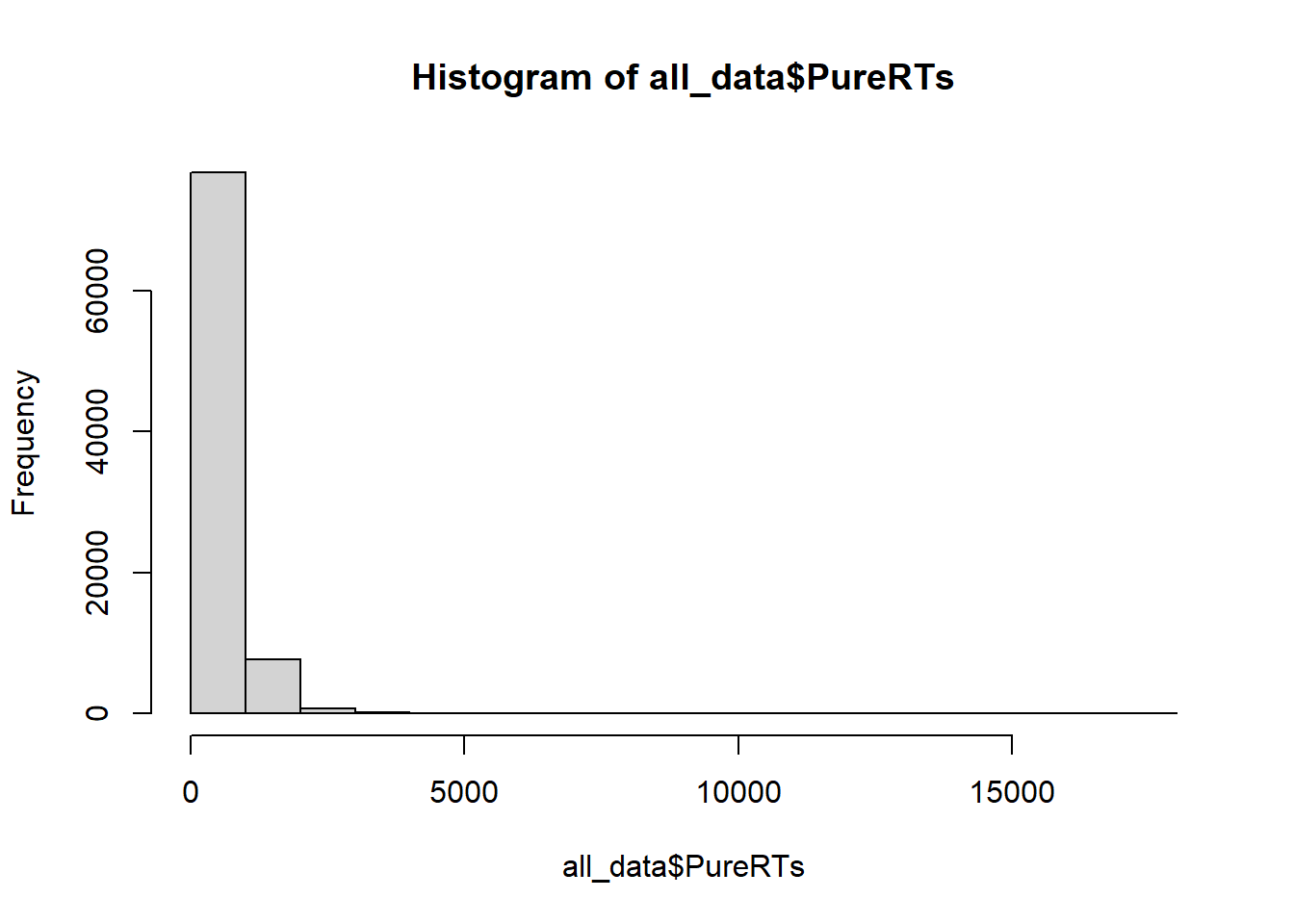
We can see that almost all of the reaction times are well below 5000 milliseconds (5 seconds), which is good. Most of the time people were paying attention and not “checking their phone”. Notice, the range of the histogram goes out to 15,000 milliseconds. You can’t see any bars out there (too small to notice), but there must be at least a few trials where somebody took 15 seconds to start responding. These are called outliers. We will remove them before we conduct our analysis
8.4.5 Look at the means
As part of looking at the data, we might as well make a figure that shows the mean reaction times in each condition, and some error bars to look at the spread in each condition. The following code takes three important steps:
- Get the means for each subject in each condition. These are put into the data frame called
subject_means. - Get the means for each condition, by averaging over the means for each subject. These are put into the data frame called
plot_means. - Make a graph with the
plot_meansdata frame using ggplot2.
library(dplyr)
library(ggplot2)
all_data$Block<-as.factor(all_data$Block)
levels(all_data$Block) <- c("Visible keyboard","Covered Keyboard")
## get subject mean RTs
subject_means <- all_data %>%
filter(Order==1, Correct==1, PureRTs<5000) %>%
group_by(Subject, Block, Stimulus) %>%
summarise(mean_rt = mean(PureRTs))
subject_means$Subject<-as.factor(subject_means$Subject)
subject_means$Block<-as.factor(subject_means$Block)
subject_means$Stimulus<-as.factor(subject_means$Stimulus)
## get condition mean RTs
plot_means <- subject_means %>%
group_by(Block, Stimulus) %>%
summarise(means = mean(mean_rt),
SEs = sd(mean_rt)/sqrt(length(mean_rt)))
## plot the condition means
# re-order stimulus factor for plotting
plot_means$Stimulus <- factor(plot_means$Stimulus, levels = c("Normal", "Bigrams", "Random"))
ggplot(plot_means, aes(x=Stimulus, y=means, group=Block, color=Block))+
geom_point()+
geom_line()+
geom_errorbar(aes(ymin=means-SEs, ymax=means+SEs), width=.2)+
theme_classic()+
ylab("Mean Reaction Time (ms)")+
xlab("Typing Material")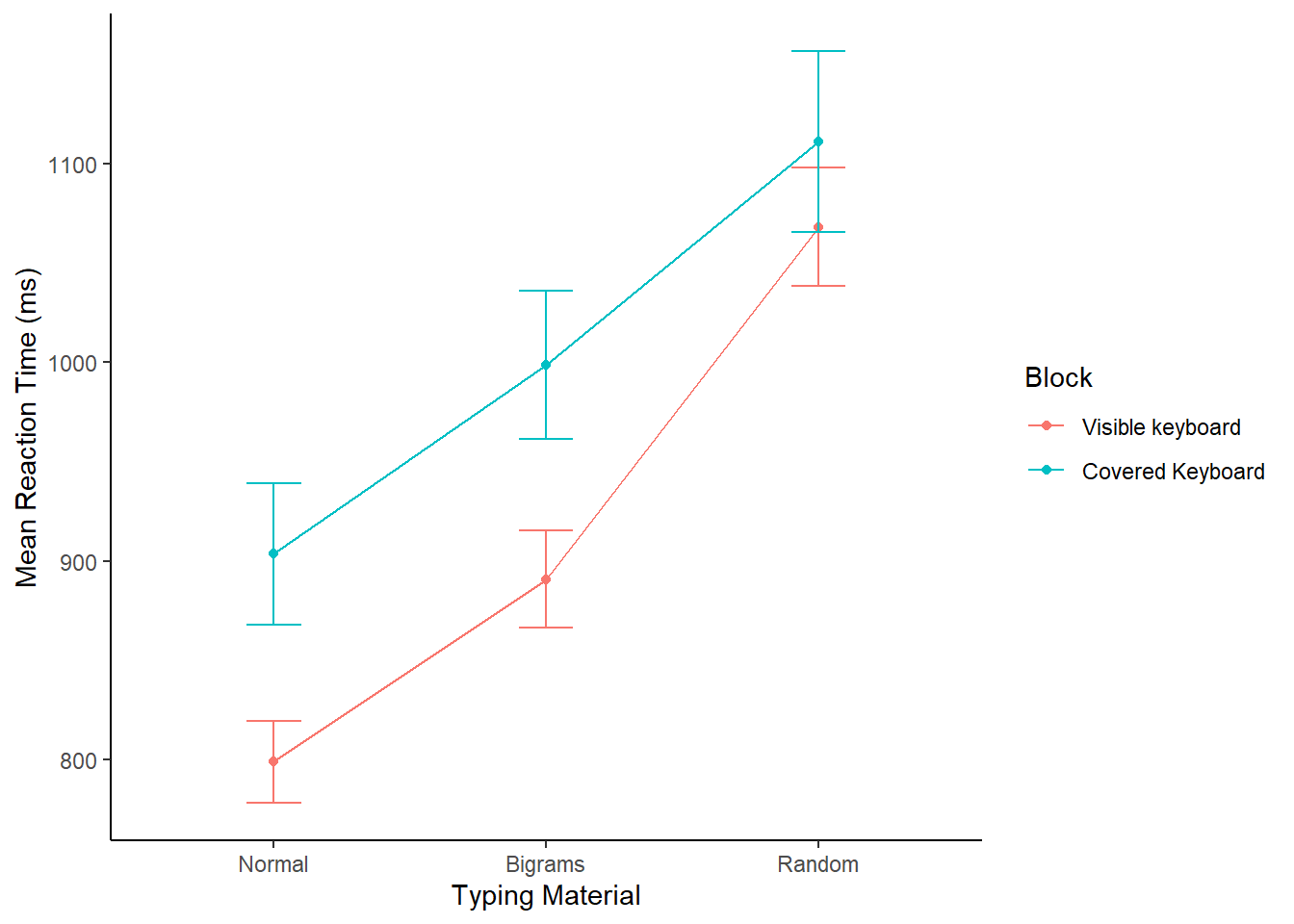
Alright, we made things a little bit more complicated than they need to be. Our primary question is whether reaction times followed this pattern: Normal < Bigrams < Random. We can see the means do follow this pattern. However, shouldn’t we only be looking at three means, why are their six means, and two lines?
The above code included the second independent variable Block. As a result, you are seeing the means for Typing material when subjects could see the keyboard, and when the couldn’t see the keyboard. We will come back to this later. For now, let’s ignore the Block condition, and find the means for the Typing Material IV by averaging over the Block conditions. We run the same code as above, by take out Block, in the group_by function. We also take Block out the ggplot function.
VERY IMPORTANT: We did something in the above code that we didn’t point out. We filtered the data before we found the means. For most of the data sets in other labs, we given you data that is more or less ready to analyse. More often than not data needs to be pre-processed, or filtered before you analyze it. We can use the filter function in dplyr to do our filtering. filter filters the rows for us, so we will only include the rows that we want.
We want to analyze the time between the onset of the stimulus and the first keystroke. The reaction times for this value are in the
PureRTscolumn, but this column contains other RTs that we do not want to analyse. For example, theOrdercolumn codes for the letter position in the string. We only want to analyze the rows that contain a1, for the first position. So, that is why we addOrder==1to the filter function below.We want to analyze only the reaction times that are correct. That is, when the subject typed the first letter correctly, and did not make a typo. Accuracy is coded in the
Correctcolumn, with 1 = correct, and 0 = incorrect. We addCorrect==1to the filtering function.
Note the use of ==, that is two equal signs in a row. In R, two equal signs in a row has a special meaning. It means conduct a logic test to determine if one thing is the same as another.
- We want to analyze only reaction times that are “sensible” to analyze. What does sensible mean? We don’t want to analyze data that is clearly garbage data. For example, if someone fell asleep at the computer and didn’t respond for 15 seconds, that kind of data is not what we want to analyze. If we were to filter the data, and exclude these kinds of
outliers, we would be conducting an outlier elimination procedure. Behmer & Crump (2017) did this, and it is commonly done in many different kinds of studies. We skip an extended discussion of outlier elimination for this lab. But, we do introduce the idea of doing it. We want to keep as much of the data as possible. So, what we do is keep all of the RTs that are less than 5000 ms (that’s 5 seconds). To do this, we addPureRTs<5000to the filter function.
## get subject mean RTs
subject_means <- all_data %>%
filter(Order==1, Correct==1, PureRTs<5000) %>%
group_by(Subject, Stimulus) %>%
summarise(mean_rt = mean(PureRTs))
subject_means$Subject<-as.factor(subject_means$Subject)
subject_means$Stimulus<-as.factor(subject_means$Stimulus)
## get condition mean RTs
plot_means <- subject_means %>%
group_by(Stimulus) %>%
summarise(means = mean(mean_rt),
SEs = sd(mean_rt)/sqrt(length(mean_rt)))
## plot the condition means
# re-order stimulus factor for plotting
plot_means$Stimulus <- factor(plot_means$Stimulus, levels = c("Normal", "Bigrams", "Random"))
ggplot(plot_means, aes(x=Stimulus, y=means, group=1))+
geom_point()+
geom_line(stat="identity")+
geom_errorbar(aes(ymin=means-SEs, ymax=means+SEs), width=.2)+
theme_classic()+
ylab("Mean Reaction Time (ms)")+
xlab("Typing Material")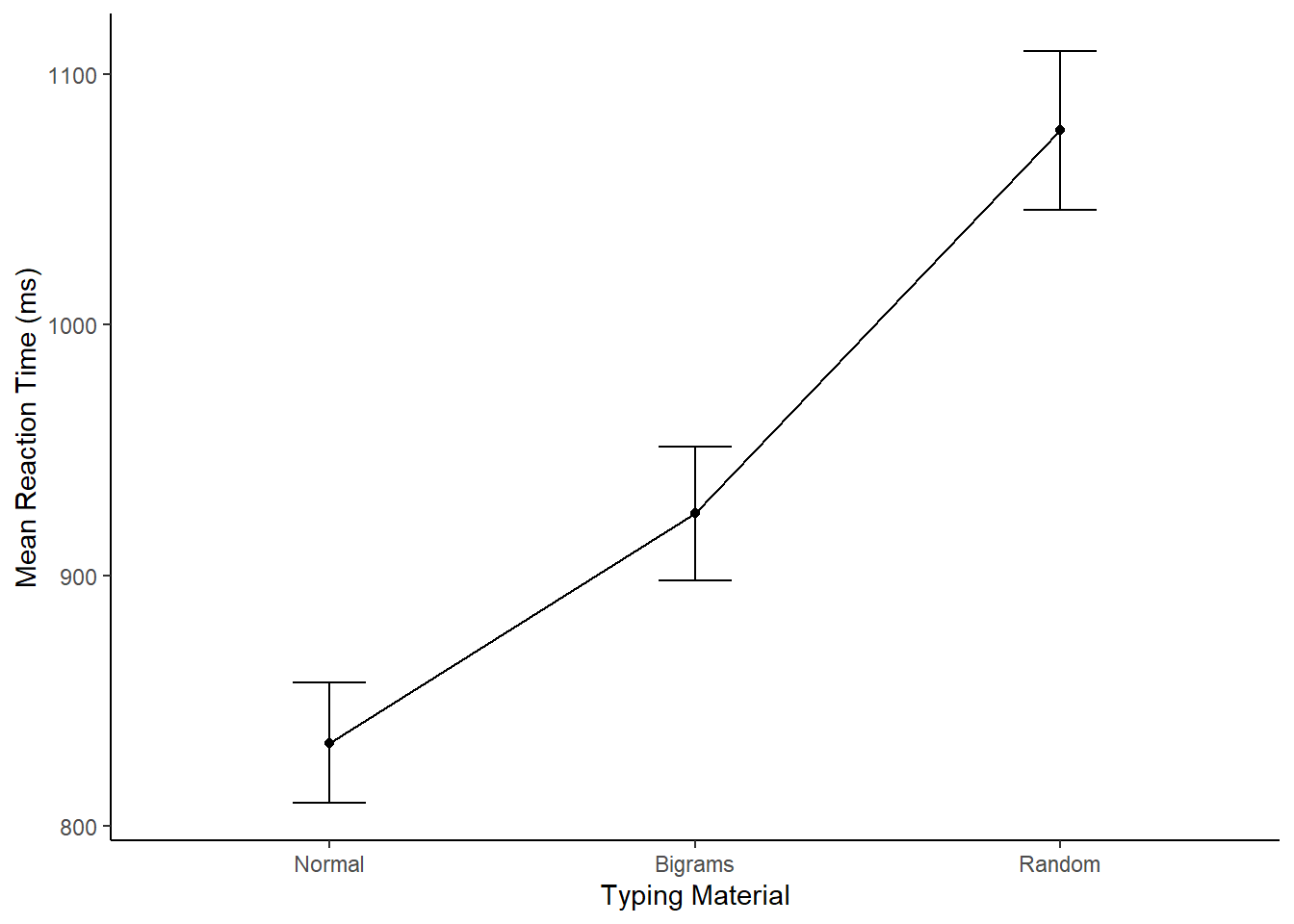
8.4.6 Conduct the repeated Measures ANOVA
We use the same aov function as we used last time. The only difference is that we add in a new part to the formula. Remember the formula for a one-factor between subjects ANOVA looked like this:
aov( DV ~ IV , dataframe), where DV is the name of the column with your independent variable, IV is the name of the column with your independent variable, and dataframe is the name of your data frame containing the means in each condition.
The formula for a repeated-measures ANOVA looks like this:
aov( DV ~ IV + Error(Subject/IV), dataframe). We have added + Error(Subject/IV). This tells R to use the appropriate error term for the repeated measures ANOVA. In the formula, Subject refers to the name of the column coding your subjects (make sure this is a factor in R), and IV is the name of the column for your independent variable.
The formula for our data would be: aov( mean_rt ~ Stimulus + Error(Subject/Stimulus), subject_means).
Here is the code below. Just as reminder, the raw data codes every single key press on each row. We don’t want to submit this as the data frame to the aov function. Instead, we need to calculate the data frame for the subject means in each condition. We did that above as a step toward making the graphs. We do it again here to remind you that you need to do this.
# get subject means
subject_means <- all_data %>%
filter(Order==1, Correct==1, PureRTs<5000) %>%
group_by(Subject, Stimulus) %>%
summarise(mean_rt = mean(PureRTs))
# Make sure IV and Subject are coded as factors
subject_means$Subject <- as.factor(subject_means$Subject)
subject_means$Stimulus <- as.factor(subject_means$Stimulus)
# Conduct the anova
aov_out <- aov( mean_rt ~ Stimulus + Error(Subject/Stimulus), subject_means)
summary_out <- summary(aov_out)
library(xtable)
knitr::kable(xtable(summary_out))| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| Residuals | 37 | 3030779.9 | 81912.970 | NA | NA |
| Stimulus | 2 | 1157965.2 | 578982.606 | 230.5806 | 0 |
| Residuals1 | 74 | 185812.3 | 2510.977 | NA | NA |
Great, we have conducted the ANOVA. We could write up the results of the ANOVA like this:
For each subject we computed mean reactions for correct keystrokes in each condition of the Stimulus factor. These means were submitted to a one-factor repeated-measures ANOVA, with Stimulus (Normal, Bigrams, and Random) as the sole factor. The effect of Stimulus was signficant, F(2, 74) = 230.58, MSE = 2510.98, p < 0.001.
Note, the p-value shows up as a zero, that’s because it is so small that R doesn’t want to print the actual number 0.000000000000000…1.
What does this tell us?
The \(F\) value we obtained (230.58) almost never occurs by chance. More specifically, the sampling distribution of F from the distribution of no differences virtually never produces a huge F like 230.58
It is super-duper unlikely that chance (sampling error) could have produced the difference we observed.
We reject the idea that chance caused the differences, and are very confident that the manipulation (changing the kinds of letters that people have to type), has a causal influence on reaction time in typing.
8.4.6.1 Report the means too
Remember, the important goal when conducting analyses, and then writing about them, is to tell people what you did and what you found. This involves more than one step. For this example, we might do three basic things. 1) make a figure to show the means, 2) report the ANOVA so people know if there is support for the inference that the differences between the means are not caused by chance, and 3) report descriptives for the means, so people know what the numbers are (the figure doesn’t show the exact values).
We’ve already made the figure and done the ANOVA, let’s report the condition means. To do this, we need to find the means for each condition, collapsing over the means for each subject in each condition. Note that, we already did this to make the figure. Here’s the code again:
## get subject mean RTs
subject_means <- all_data %>%
filter(Order==1, Correct==1, PureRTs<5000) %>%
group_by(Subject, Stimulus) %>%
summarise(mean_rt = mean(PureRTs))
subject_means$Subject<-as.factor(subject_means$Subject)
subject_means$Stimulus<-as.factor(subject_means$Stimulus)
## get condition mean RTs
plot_means <- subject_means %>%
group_by(Stimulus) %>%
summarise(means = mean(mean_rt),
SEs = sd(mean_rt)/sqrt(length(mean_rt)))
knitr::kable(plot_means)| Stimulus | means | SEs |
|---|---|---|
| Bigrams | 924.8764 | 26.69375 |
| Normal | 833.1872 | 24.00055 |
| Random | 1077.5361 | 31.60979 |
Now, our full write-up of the results would look like this.
For each subject we computed mean reactions for correct keystrokes in each condition of the Stimulus factor. These means were submitted to a one-factor repeated-measures ANOVA, with Stimulus (Normal, Bigrams, and Random) as the sole factor. The effect of Stimulus was signficant, F(2, 74) = 230.58, MSE = 2510.98, p < 0.001. The mean reaction time was fastest in the Normal condition (M = 833 ms, SE = 24 ms), followed by the Bigram condition, (M = 924 ms, SE = 27 ms) and slowest in the Random Condition (M = 1078 ms, SE = 32 ms).
8.4.7 Follow-up comparisons
The ANOVA tells us that the differences between the means are unlikely to be due to chance. But, remember, this is an omnibus test. It does not tell us if specific pairs of means are different from one another. To determine whether the difference between two specific means is not likely due to chance, we need to conduct follow-up tests.
Because this is a repeated-measures design, we can use the paired-samples t-test for follow-up tests. Let’s do two follow-up tests to confirm that the RTs for Normal words were indeed faster than the RTs for the Bigram condition (word-like non-words); and then, let’s confirm that the RTs for the Bigram condition were indeed faster than the RTs for the Random condition.
8.4.7.1 Normal vs Bigrams
We use the subject_means data frame. But, we want to rid of all the rows containing the means from the Random condition. We use filter to do that, then we conduct the paired-samples t-test.
comparison_df <- subject_means %>%
filter(Stimulus != "Random")
t.test(mean_rt~Stimulus,
paired=TRUE,
var.equal=TRUE,
data = comparison_df)##
## Paired t-test
##
## data: mean_rt by Stimulus
## t = 12.14, df = 37, p-value = 1.807e-14
## alternative hypothesis: true mean difference is not equal to 0
## 95 percent confidence interval:
## 76.38601 106.99253
## sample estimates:
## mean difference
## 91.689278.4.7.2 Bigrams vs Random
We use the subject_means data frame. But, we want to rid of all the rows containing the means from the Normal condition. We use filter to do that, then we conduct the paired-samples t-test.
comparison_df <- subject_means %>%
filter(Stimulus != "Normal")
t.test(mean_rt~Stimulus,
paired=TRUE,
var.equal=TRUE,
data = comparison_df)##
## Paired t-test
##
## data: mean_rt by Stimulus
## t = -14.212, df = 37, p-value < 2.2e-16
## alternative hypothesis: true mean difference is not equal to 0
## 95 percent confidence interval:
## -174.4245 -130.8949
## sample estimates:
## mean difference
## -152.65978.4.8 Reporting everything
Now we can look at some write-ups that report everything we did, and everything we want to know. I’ll show you two ways to do it.
8.4.8.1 First way
In the first way, we embed the results of the t-test into the description of the mean reaction times.
For each subject we computed mean reactions for correct keystrokes in each condition of the Stimulus factor. These means were submitted to a one-factor repeated-measures ANOVA, with Stimulus (Normal, Bigrams, and Random) as the sole factor. The effect of Stimulus was significant, F(2, 74) = 230.58, MSE = 2510.98, p < 0.001. The mean reaction time was significantly faster in the Normal condition (M = 833 ms, SE = 24 ms), compared to the Bigram condition, (M = 924 ms, SE = 27 ms), t(37) = 12.14, p<0.001. Additionally, mean reactions in the Bigram condition were significantly faster than the Random Condition (M = 1078 ms, SE = 32 ms), t(37) = 14.21, p < 0.001.
8.4.8.2 Second way
In the second way, we first report the means as we did the very first time, and then after that we report the t-test results to highlight the size the of the differences between each comparison.
For each subject we computed mean reactions for correct keystrokes in each condition of the Stimulus factor. These means were submitted to a one-factor repeated-measures ANOVA, with Stimulus (Normal, Bigrams, and Random) as the sole factor. The effect of Stimulus was significant, F(2, 74) = 230.58, MSE = 2510.98, p < 0.001. The mean reaction time was fastest in the Normal condition (M = 833 ms, SE = 24 ms), followed by the Bigram condition, (M = 924 ms, SE = 27 ms) and slowest in the Random Condition (M = 1078 ms, SE = 32 ms). Mean reaction times were significantly faster (M = 91 ms) in the Normal than Bigrams condition, t(37) = 12.14, p < 0.001. And, mean reaction times were significantly faster (M = 152 ms) in the Bigrams than Random condition, t(37) = 14.21, p < 0.01.
There are other ways to write-up statistical results. These are just some example recipes. The important thing is to:
- Say what the numbers were that you are analyzing
- Say what the statistical test was
- Say the results of the statistical test
- Say what the patterns of means were
- Say what the follow-up tests were when you test differences between specific means.
- Add a table or figure so it is easier to “see” the results.
8.4.9 Generalization Exercise
Your task is to conduct another repeated-measures ANOVA. Rather than using the reaction time for the first-keystroke as the dependent measure, you will use the reaction times between all of the keystrokes in each word, these are called interkeystroke intervals. The Order variable is used to code keystroke position (1 to 5). You will want to analyze only the PureRTs that have an Order greater than 1. For example, you could use the following code to get the subject_means for the mean interkeystroke intervals.
subject_means <- all_data %>%
filter(Order > 1, Correct==1, PureRTs<5000) %>%
group_by(Subject, Stimulus) %>%
summarise(mean_rt = mean(PureRTs))A. Make a figure for the new DV B. Report the ANOVA table for the new repeated measures ANOVA C. Discuss whether the general pattern is the same as before.
8.4.10 Writing assignment
(2 points - Graded)
Explain the concept of \(SS_\text{Total}\) (.5 points)
Explain the concept of partitioning SS_ into smaller pieces. What is the goal of the spitting? (.5 points)
Explain the major difference between a between-subjects ANOVA and repeated-measures ANOVA in terms of what is being partioned. (1 point)
General grading.
- You will receive 0 points for missing answers
- You must write in complete sentences. Point form sentences will be given 0 points.
- Completely incorrect answers will receive 0 points.
- If your answer is generally correct but very difficult to understand and unclear you may receive half points for the question
8.6 SPSS
In this lab, we will use SPSS to:
- Produce a frequency histogram and remove outliers
- Conduct and graph One-Factor Repeated Measures ANOVA
- Conduct planned comparisons using a paired-samples t-test
8.6.1 Experiment Background
In this experiment, Behmer and Crump (2017) recruited 38 subjects to type words presented on a screen as quickly as they could. The independent variable was typing material and it had 3 levels: Normal (5 letter English words), Bigrams (5 letter non-words that have properties like real words), and Random (random 5 letter strings). The authors wanted to know whether reaction time (RT) was different according to the type of word being typed.
Dependent Variables: There were three dependent variables, that all measured different aspects of typing performance. Reaction times (RTs) were defined as the temporal interval between seeing a stimulus (to type), and then starting to type it (first key press). Inter-keystroke intervals (IKSIs) are the times between each key-press. Last, accuracy was also measured (correct or incorrect key-presses). For this analysis we will use Pure RTs as our one DV.
Nota bene: This is a repeated measures design because each participant typed letter strings from the word, bigrams, and random conditions.
8.6.2 Produce a frequency histogram and remove outliers
Here is a link to the data file. It is named BehmerCrump.sav. Your data should look like this:
First, we’ll be creating a histogram to look at our data. Go to Graphs, then Legacy Dialogs, then Histogram…
The next window will ask you to specify the variable you would like graphed. Choose PureRTs from the list on the left and move it into the “Variable” field using the arrow.
Click OK. SPSS will produce a frequency histogram of your data.
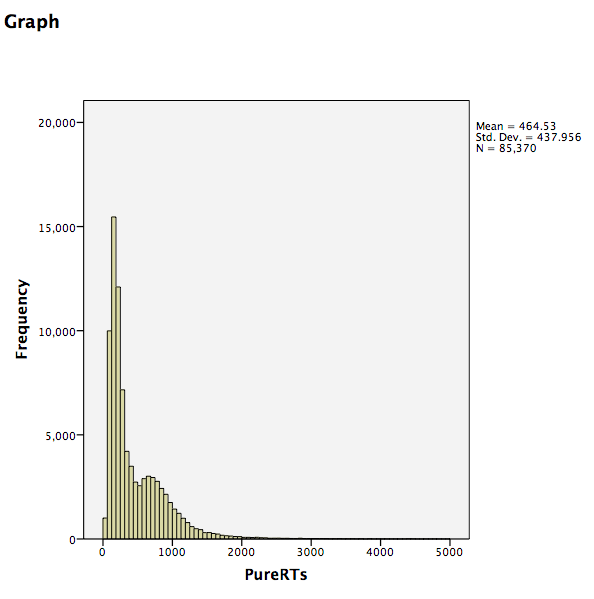
Notice that the RTs form a positively skewed distribution. Most RT measurements are on the lower end of the scale, and there are very few RTs that are higher than 5000ms. These measurements could have resulted from subjects falling asleep, looking at their phones, or being otherwise distracted in the middle of the experiment. We want to remove those values so they do not influence and mischaracterize our results. To do this, go to the top menu and choose Data, then Select Cases…
The next window will ask you which cases to select. We specifically want to remove any cases larger than 5000, so check off If condition is satisfied:
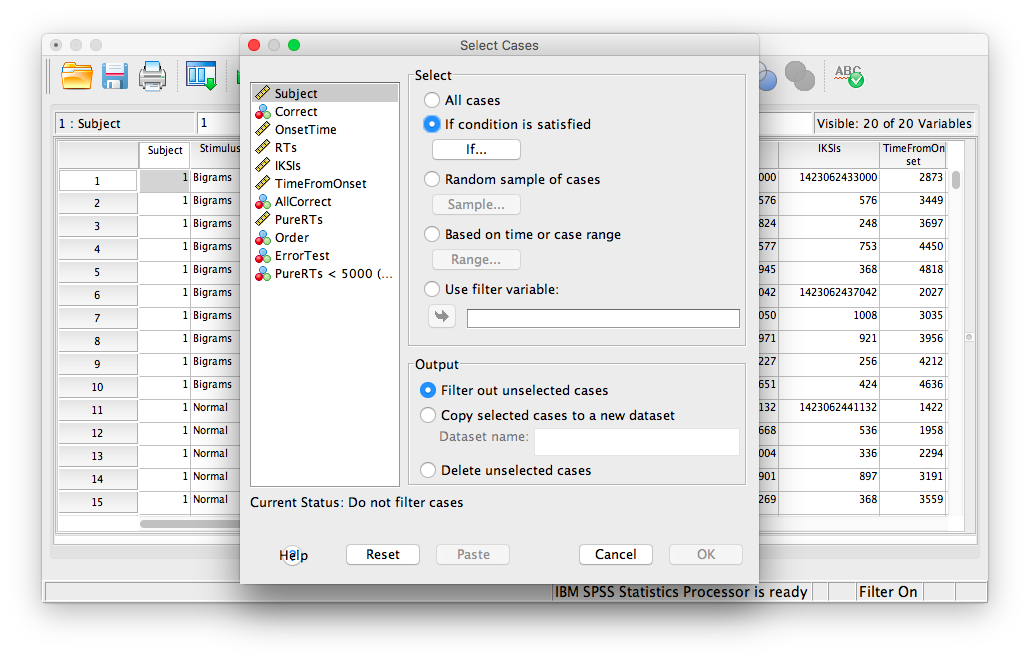
Then click If… The window that follows will ask you to specify the condition for inclusion. Find the variable PureRTs in the left-hand list and move it to the field on top using the arrow. Then, type “< 5000” to specify that we want to keep only values under 5000ms.
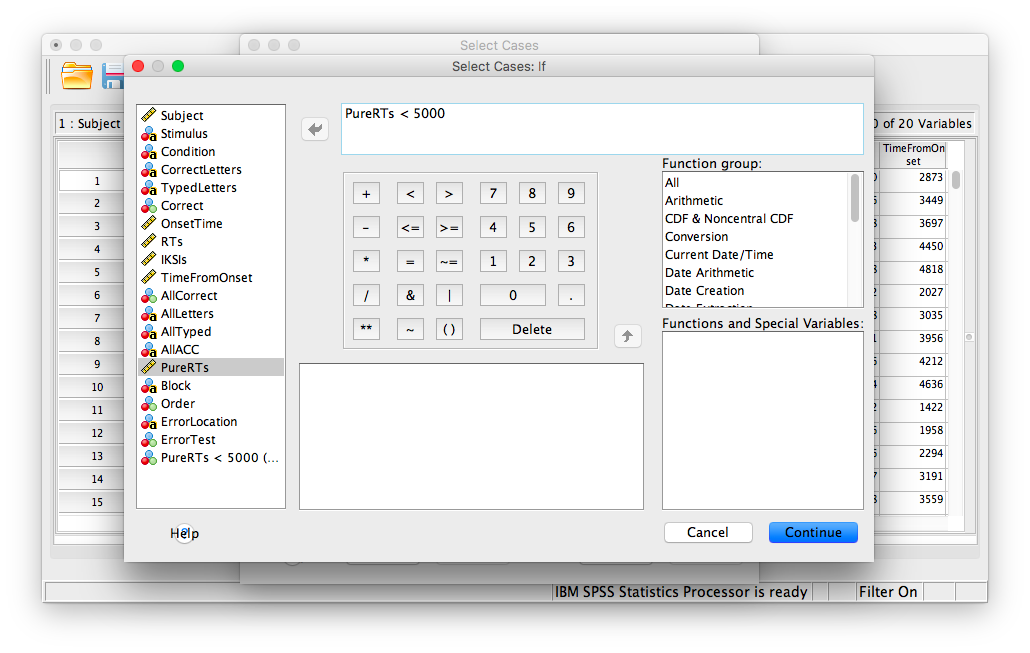
Click Continue. Your data has now been edited so that trials on which the PureRTs value was greater than 5000 have been removed.
Let’s take some time to think about this data. We have measurements taken from many participants across multiple trials and multiple conditions. Our goal is to be able to come up with a single RT for each person per condition. The only way to do this is to take an individual’s RTs for a particular condition and average them. To do this, we need to calculate means. First, go to Analyze, then Compare Means, then Means…
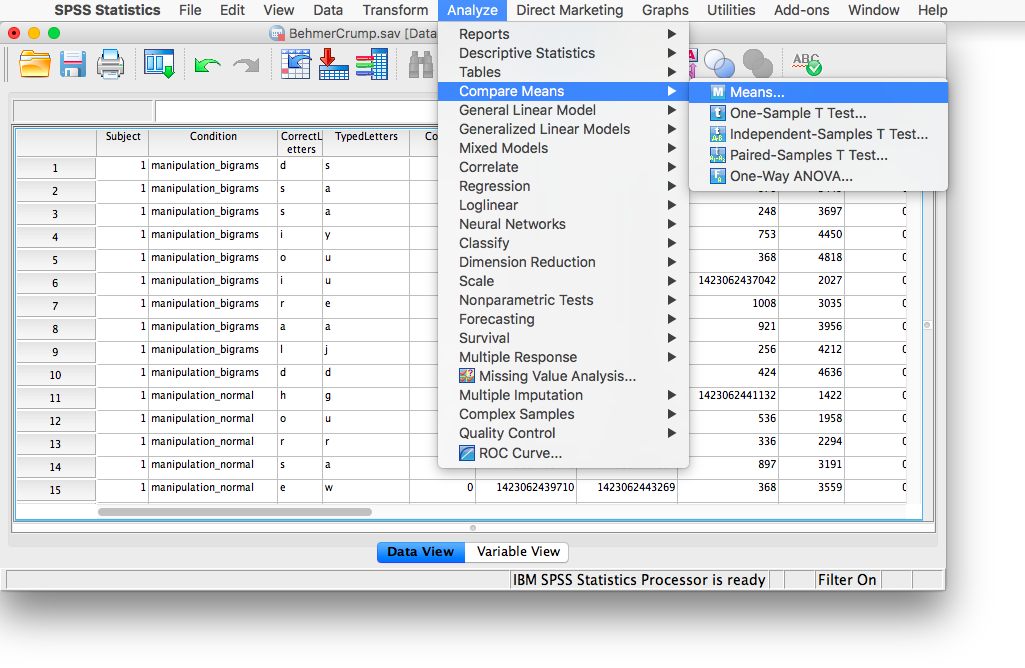
In the next window, move the PureRTs variable into the “Dependent List” field. In the field below, labeled “Independent List”, place the Subject variable:
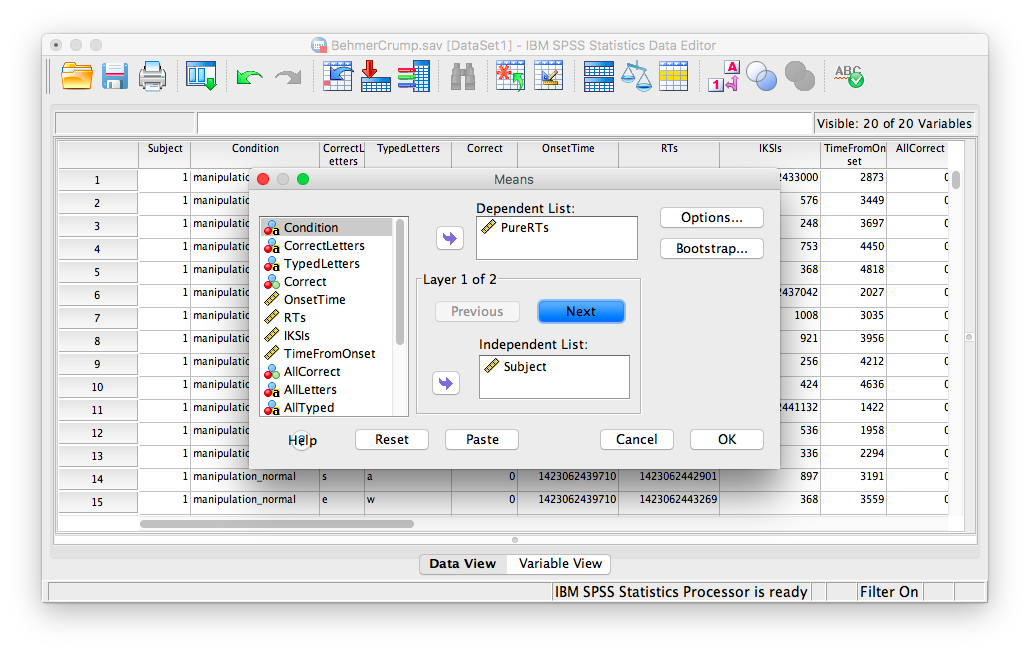
Then, click Next. The bottom field will become blank again, and you can now place the Stimulus variable into it.
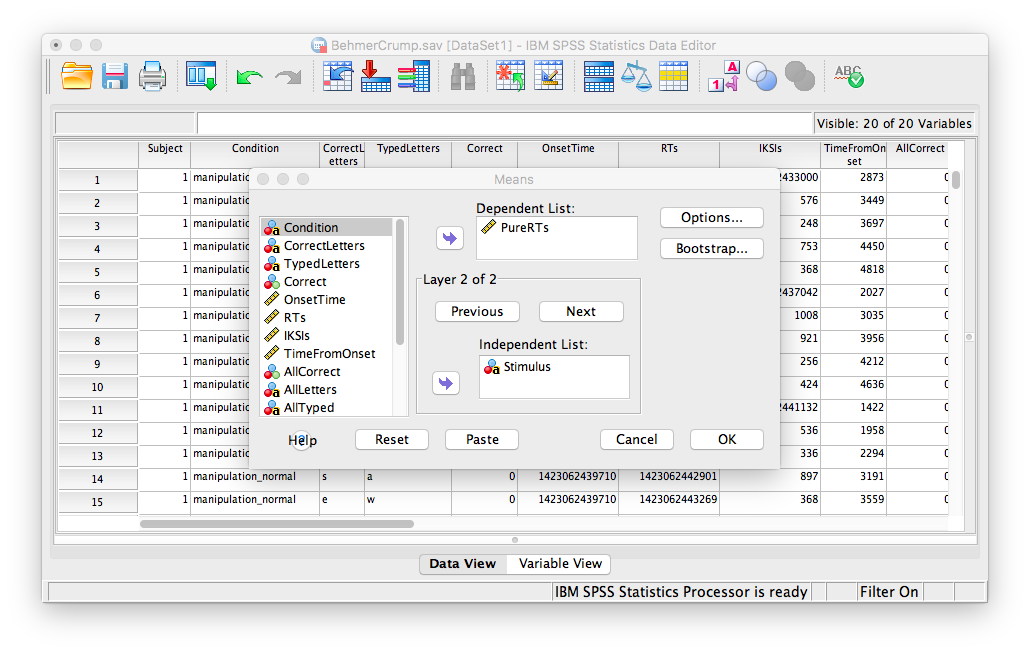
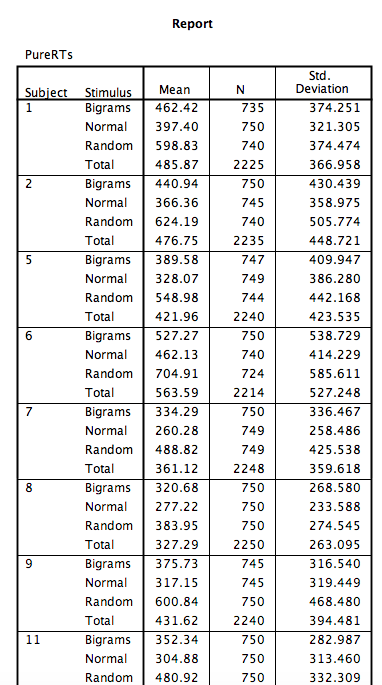
Click OK. SPSS will produce an output table containing each subject’s average RT per condition:
8.6.3 Conduct and graph One-Factor Repeated Measures ANOVA
For this part of the tutorial, we will switch over to a new SPSS file. Here is the link; it’s called BehmerCrumpMeanRTs.sav. When you open the file, it should look like this:
Notice that this file contains the means from the table we just created. Each person’s data is contained within a row: there are 3 measurements corresponding to all stimulus conditions. To calculate a One-Factor Repeated Measures ANOVA, go to Analyze, then General Linear Model, then Repeated Measures…
The next window will ask you to label your within-subjects variable. Type Stimulus into the “Within-Subjects Factor Name” field. Indicate that this variable has 3 levels. Then click Add, and then Define.
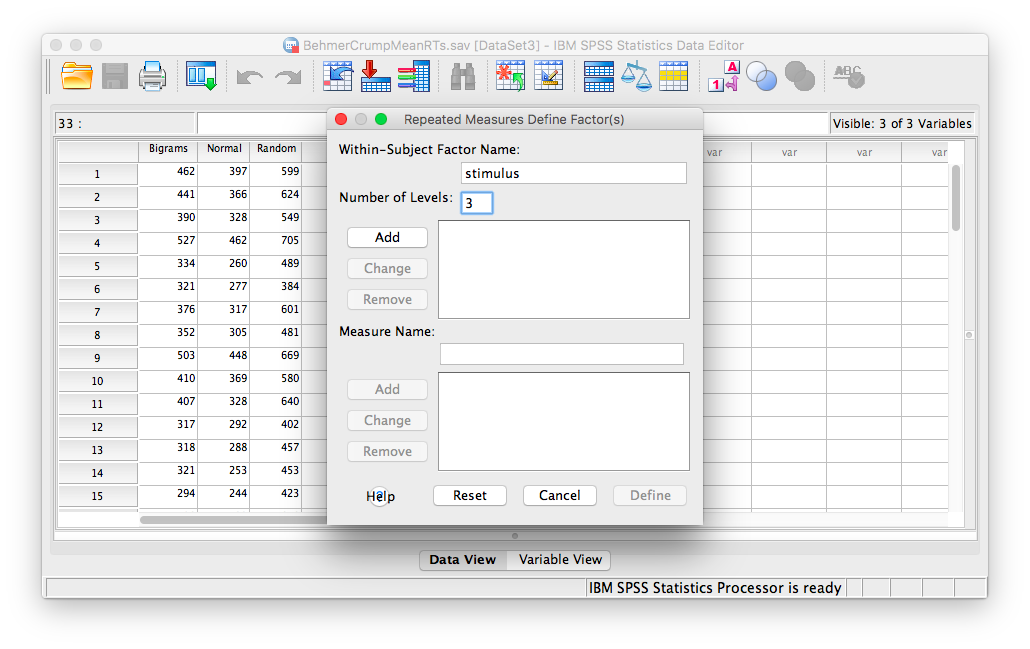
In the next window, move all 3 conditions listed on the left into the “Within-Subjects Variables” field.
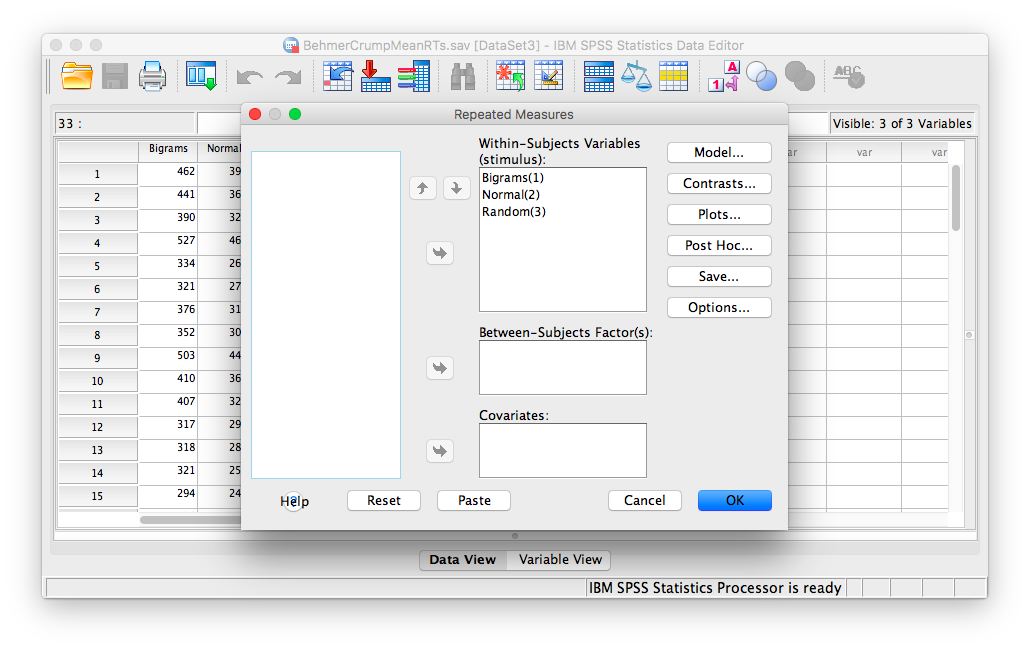
Click OK. SPSS will produce an output table labeled “Tests of Within-SUbjects Effects” that contains The F statistic and its corresponding p-value.
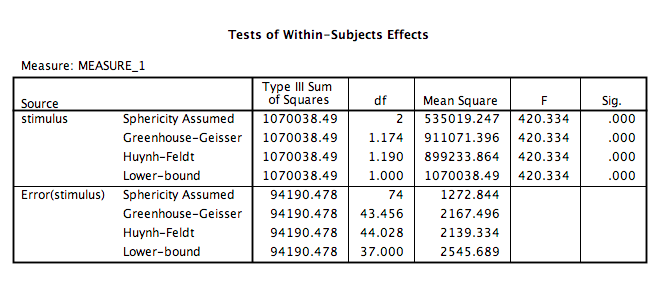
From this table, we see that there is a significant effect of stimulus on RT, F(2, 74)= 420.33, p<.05. In order to graph this data and look at the means, go to Graphs, then Legacy Dialogs, then Bar…
In the next window, choose Simple, but this time select Summaries of separate variables, then Define:
In the next window, move the three stimulus conditions listed in the field on the left into the field labeled “Bars Represent.”
Then click OK. SPSS will produce a bar graph with each bar representing the mean of each of the conditions. We can see that the Random condition has the longest RT, followed by Bigrams, and then Normal. However, at this point we do not know which groups are significantly different from the others.
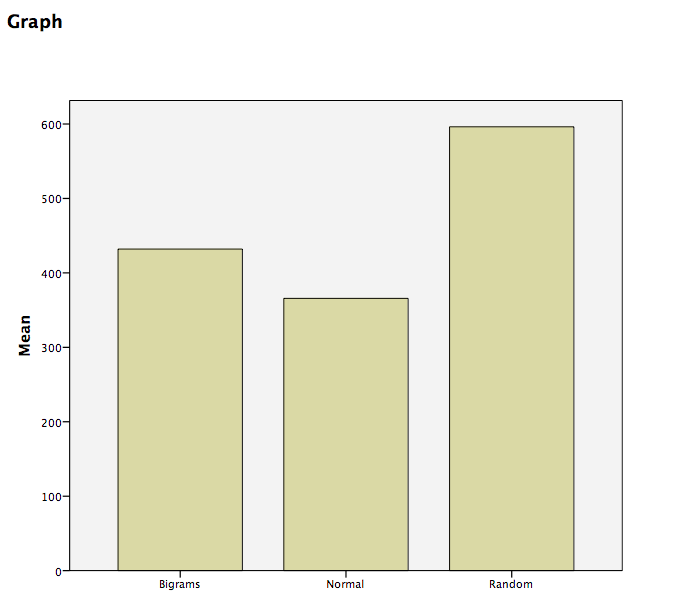
8.6.4 Conduct planned comparisons using a paired-samples t-test
To find out where the difference among these 3 conditions exists, we will use a planned comparison in the form of a paired-samples t-test. This method takes 2 groups at a time and tests for pairwise differences. There are three comparisons that can be made here:
- normal vs. bigram
- bigram vs. random
- random vs. normal
We will use a paired-samples t-test instead of an independent-samples t-test because in each comparison, the same people are being remeasured in each group.
To begin, go to Analyze, then Compare Means, then Paired Samples T-test…
In the next window, move the two conditions of our first pairwise comparison (normal vs. bigram) into the field on the right using the arrow.
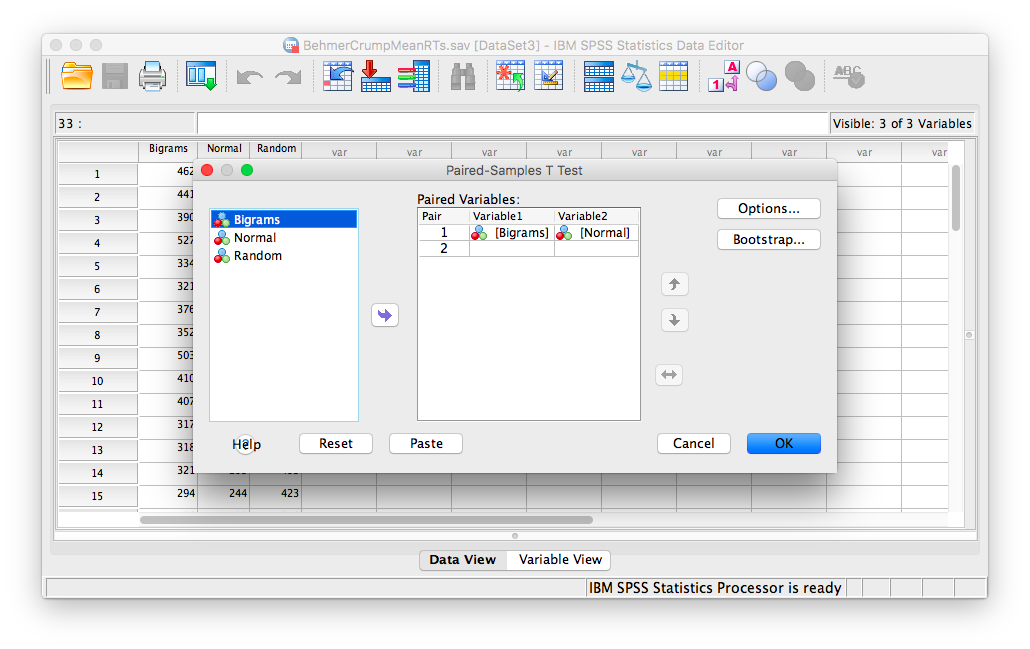
Click OK. SPSS will produce a series of tables. The “Paired Samples test” table contains the t-statistic and its associated p-value.
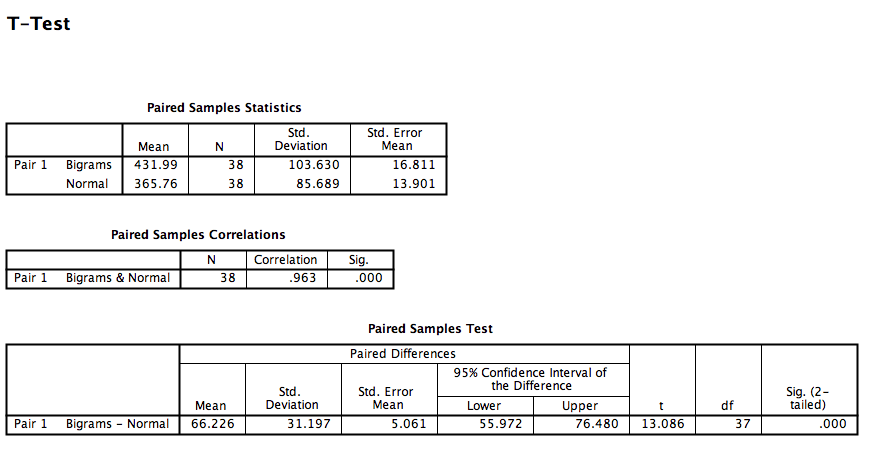
Looking at this output, we can see that the Normal and Bigrams conditions are indeed significantly different, t(37)= 13.09, p<.05.
You can use this same method for the remaining comparisons.
8.6.5 Practice Problems
Run the same analysis as illustrated in this lab tutorial but with accuracy (correct) as the dependent variable. Use an alpha level of .05. Remember to calculate means per subject and stimulus first. This will generate a table, whose values you can enter into a new SPSS spreadsheet file.
Is there an effect of stimulus on error rate? If so, conduct the appropriate planned comparisons.
Graph the means using a bar graph; include +/-1 SEM Error bars.
8.7 JAMOVI
This section is copied, almost verbatim, with some editorial changes, from Answering questions with data: The lab manual for R, Excel, SPSS and JAMOVI, Lab 8, Section 8.6, SPSS, according to its CC license. Thank you to Crump, Krishnan, Volz, & Chavarga (2018).
In this lab, we will use JAMOVI to:
- Conduct and graph One-Factor Repeated Measures ANOVA
- Conduct follow-up tests
8.7.1 Experiment Background
As described in more detail at the beginning of this lab manual section, Behmer and Crump (2017) recruited 38 subjects to type words presented on a screen as quickly as they could. The independent variable was typing material and it had 3 levels: Normal (5 letter English words), Bigrams (5 letter non-words that have properties like real words), and Random (random 5 letter strings). The authors wanted to know whether reaction time (RT) was different according to the type of word being typed.
Dependent Variables: There were three dependent variables, that all measured different aspects of typing performance. Reaction times (RTs) were defined as the temporal interval between seeing a stimulus (to type), and then starting to type it (first key press). Inter-keystroke intervals (IKSIs) are the times between each key-press. Last, accuracy was also measured (correct or incorrect key-presses). For this analysis we will use Mean RTs as our one DV.
Nota bene: This is a repeated measures design because each participant typed letter strings from the Normal, Bigrams, and Random conditions.
8.7.2 Checking Assumptions
Recall that the Repeated Measures ANOVA assumes:
The sampling distributions are normally distributed. Consider the central limit theorem and/or histograms.
The data are measured using an interval or a ratio scale. Consider what you know about how the data were collected and/or look at the variable attributes in the JAMOVI data spreadsheet.
The data are spherical. (No two conditions are any more dependent than any other two. OR There is equal correlation among pairs of conditions. OR There is equal variance among differences between pairs of conditions.) To test this, we use Mauchly’s test. This test can be requested when you run the Repeated Measures ANOVA in JAMOVI.
Challenge: On your own and using the data set to be used in our lab demonstration, check the first two assumptions. Were these assumptions met or violated? How do you know? (Be prepared to answer these questions at the beginning of lab.)
8.7.3 Conduct and graph One-Factor Repeated Measures ANOVA
Here is the link to the data set we will use; it’s called BehmerCrumpMeanRTs.omv. When you open the file, it should look like this:
Notice that this file contains means. Each person’s data is contained within a row: there are 3 measurements corresponding to all stimulus conditions. To calculate a One-Factor Repeated Measures ANOVA, go to Analyses, ANOVA, and then Repeated Measures ANOVA.
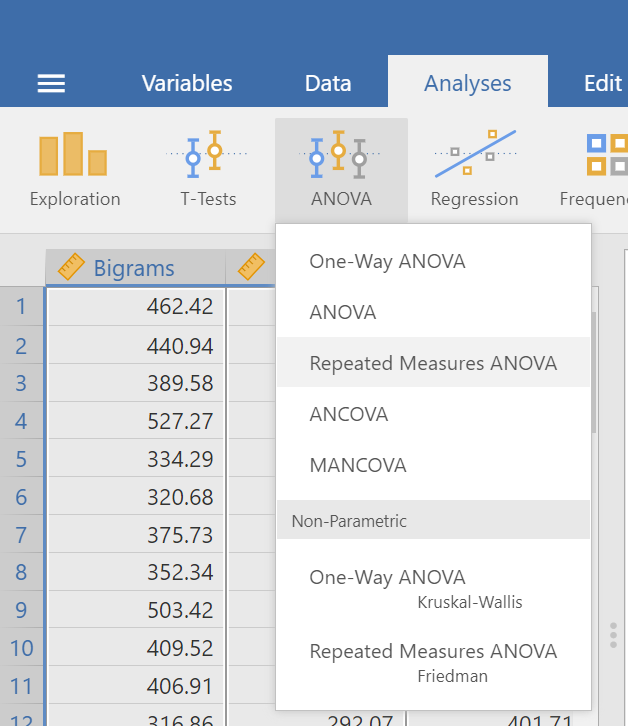
In the pane where you enter the commands, you can label your within-subjects variable. In the window called “Repeated Measures Factors,” type the name after highlighting or clicking in the area where you read “RM Factor 1”. Remember, we are looking at a One-Factor Repeated Measures ANOVA, so we only need to concern ourselves with this section. In other words, we do not have other “factors” to consider (We can ignore “RM Factor 2”.).
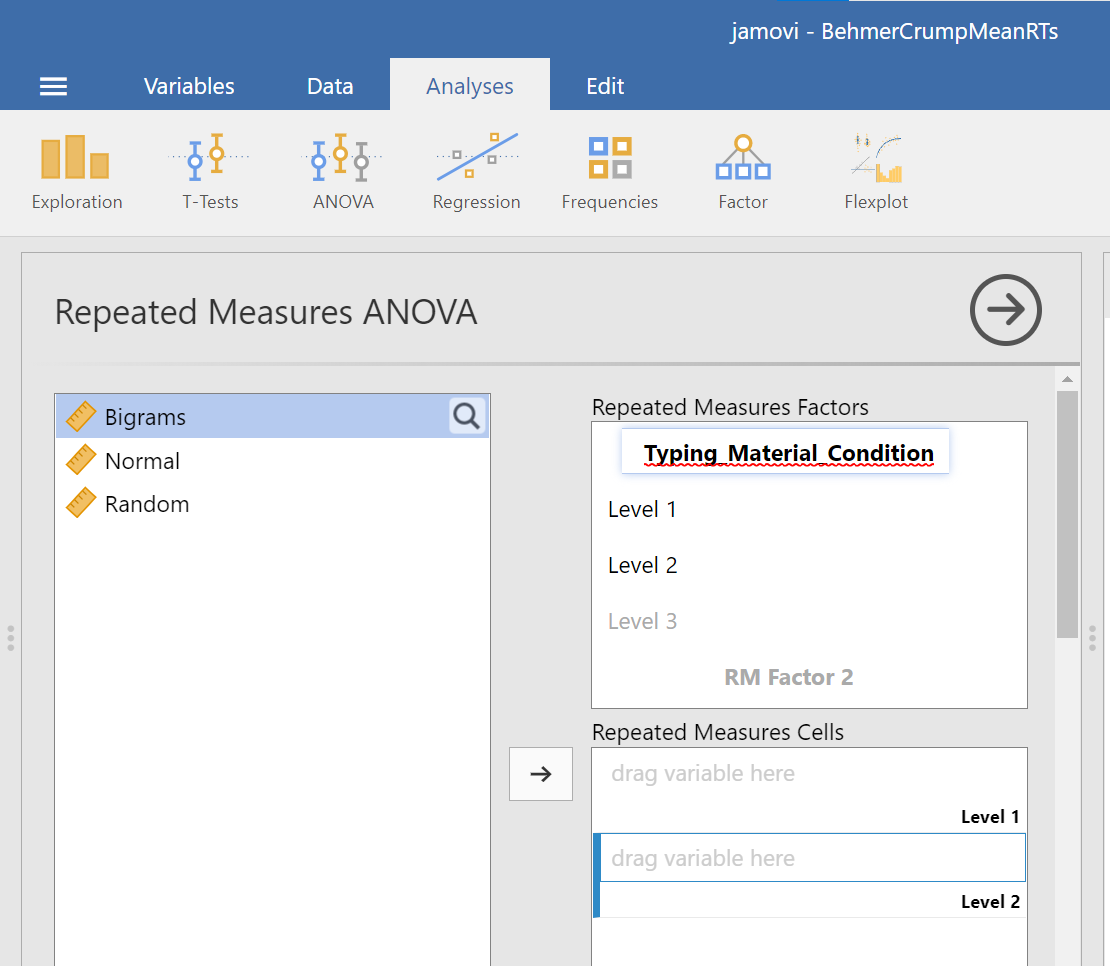
At this point, we need to define the levels of this factor. Notice that only two levels are being displayed in JAMOVI under the “Repeated Measures Factors” window. In its font colour, “Level 3” is light grey, rather than black. (Even if we move the names of the levels into the “Repeated Measures Cells,” JAMOVI does not rename the levels above.) If you want the names of the levels to show in your output, type the names of the levels in where you see Level 1, Level 2, and so on in the “Repeated Measures Factors” window.
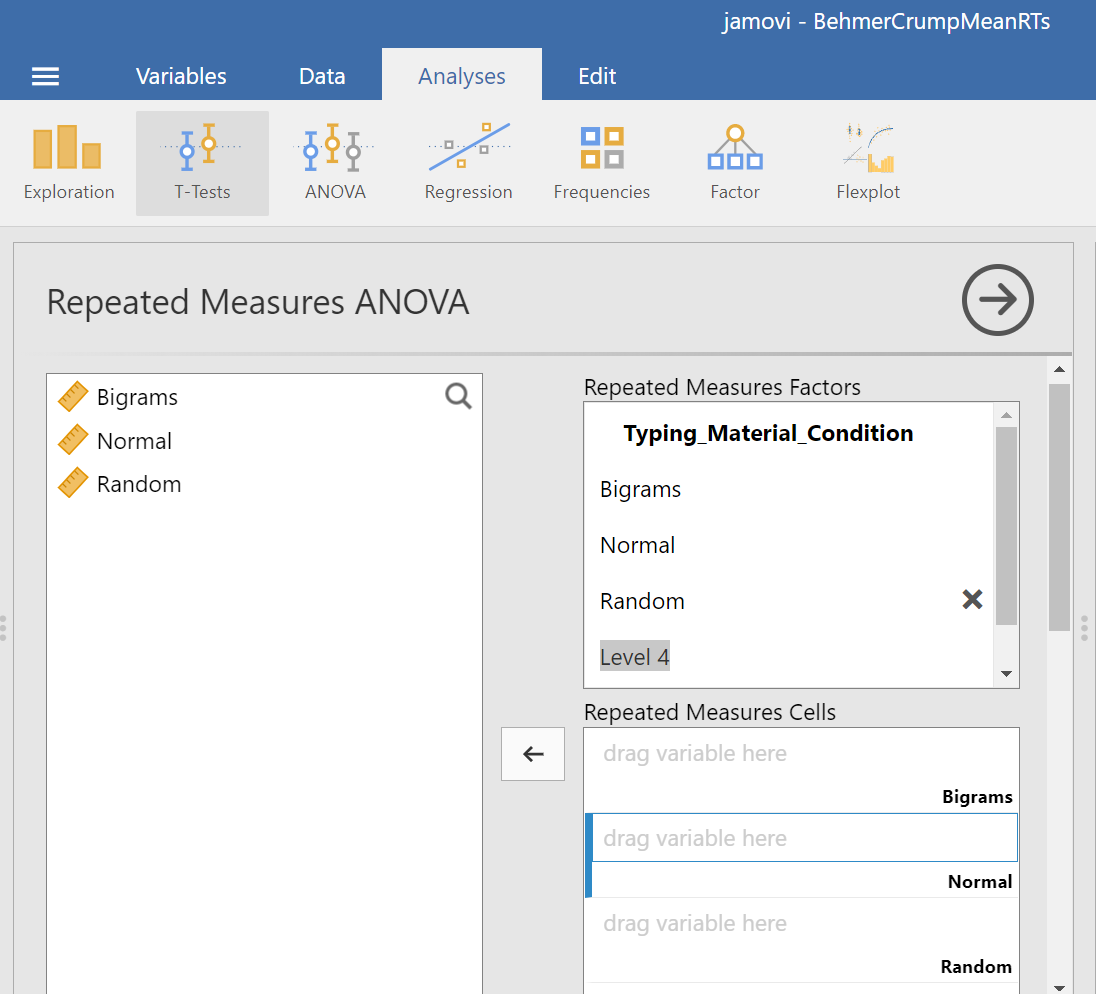
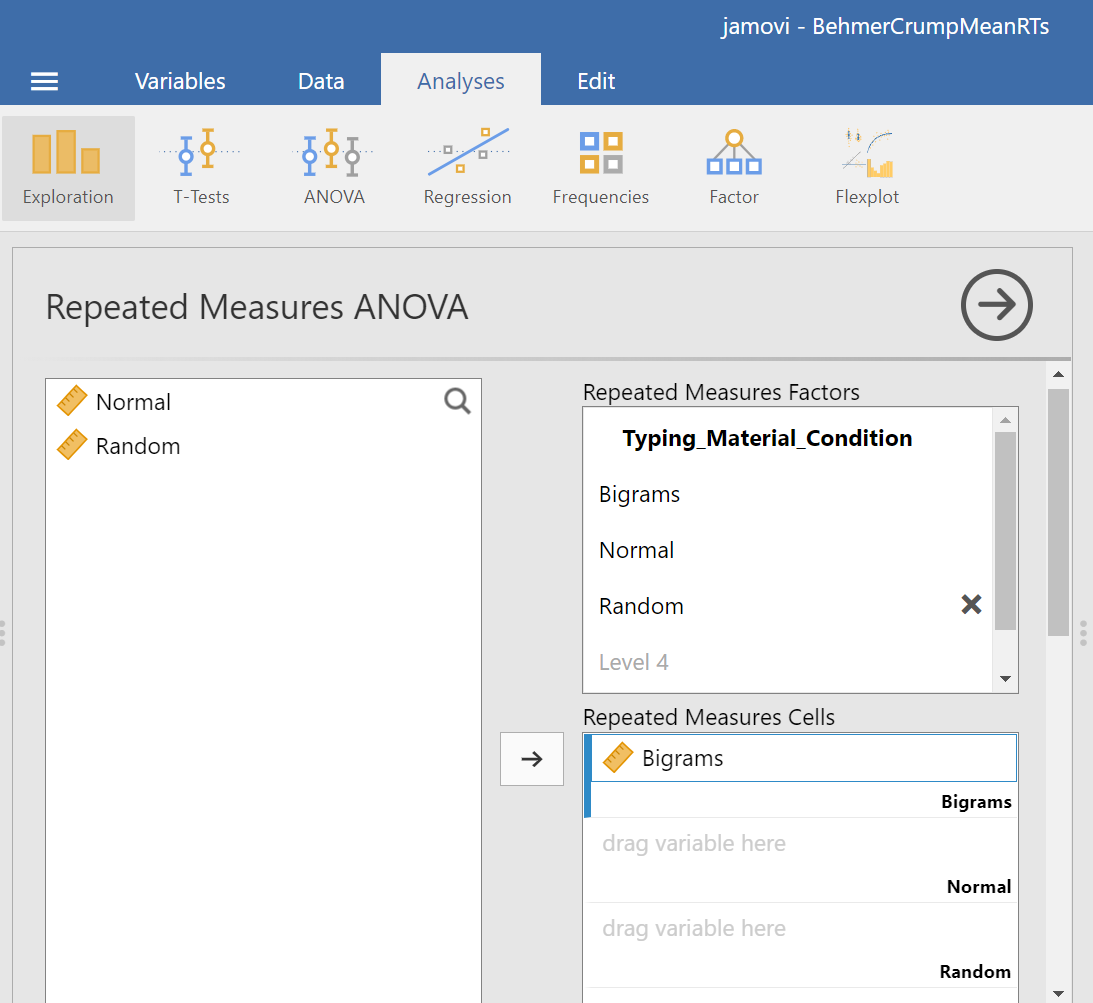
Then, you should highlight and drag each and every level of the factor (aka variable) from the window on the left to the corresponding area in the “Repeated Measures Cells” window on the right.
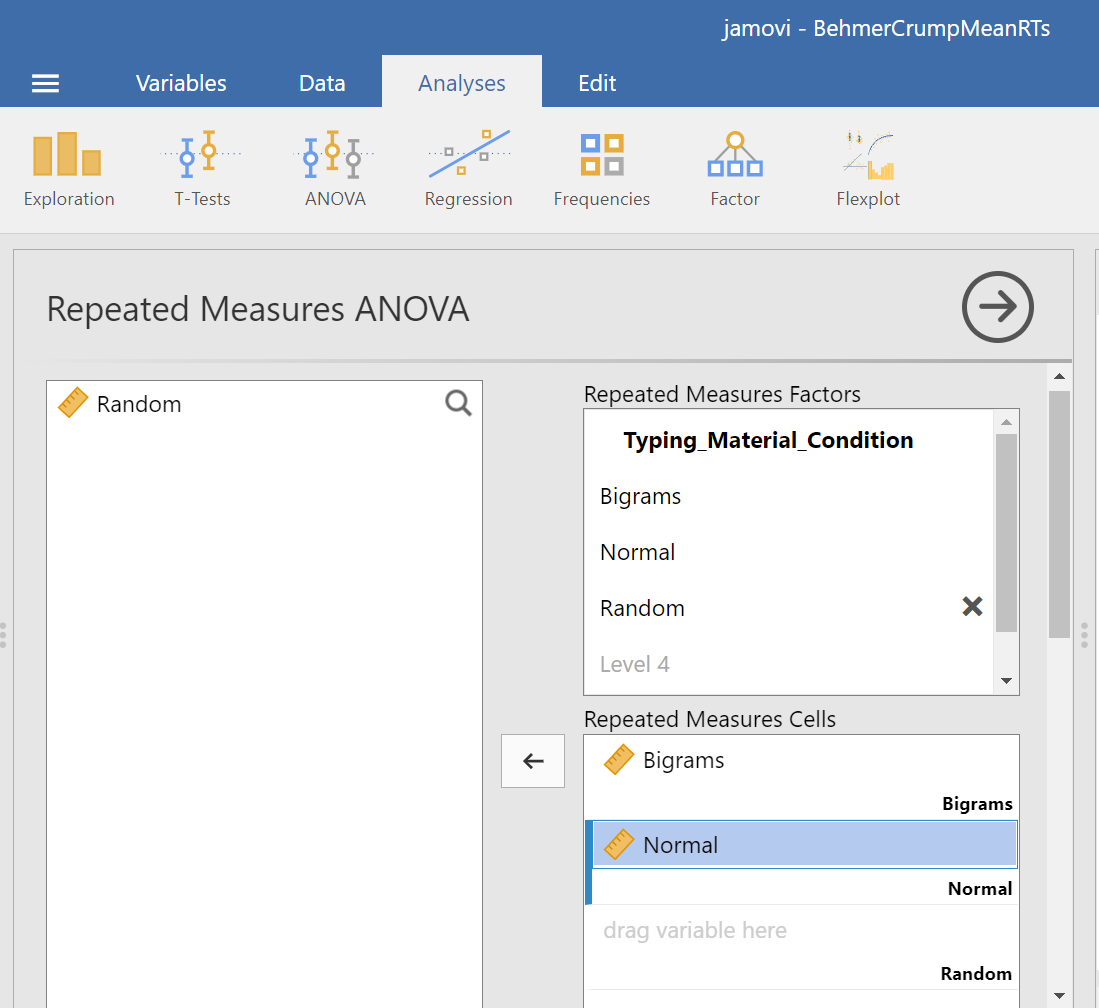

Before we can look at the results JAMOVI has been generating in the Results pane, we should request Mauchly’s test. To do this, move down in commands pane (on the left), and under the “Assumption Checks” ribbon, select Sphericity tests. Just in case the assumption of sphericity is violated, you could request corrections at this time; click Greenhouse-Geisser.
JAMOVI will produce a few tables in the Results pane. Much like you checked the results of Levene’s test before moving ahead to read the One-Way ANOVA table (when you performed a One-Factor or One-Way ANOVA), you should check the results of Mauchly’s test before moving ahead to read the Repeated Measures ANOVA table. Let’s do that; let’s check the results of Mauchly’s test.
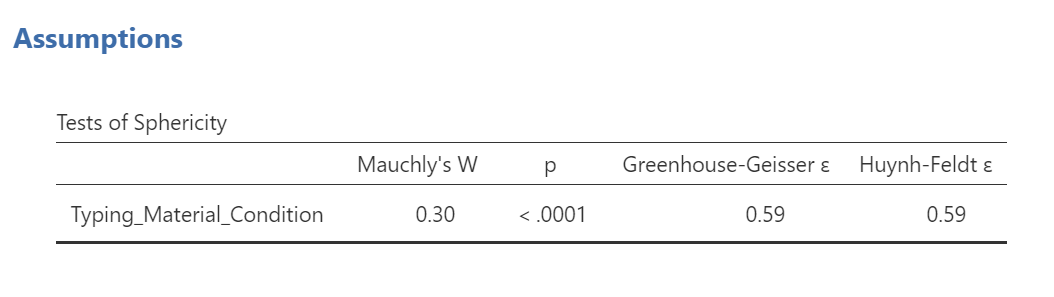
Mauchly’s test indicates a significant result, p < .0001. The assumption of sphericity is violated. We should read the results of the Repeated Measures ANOVA table with the sphericity correction, the Greenhouse-Geisser correction, applied.
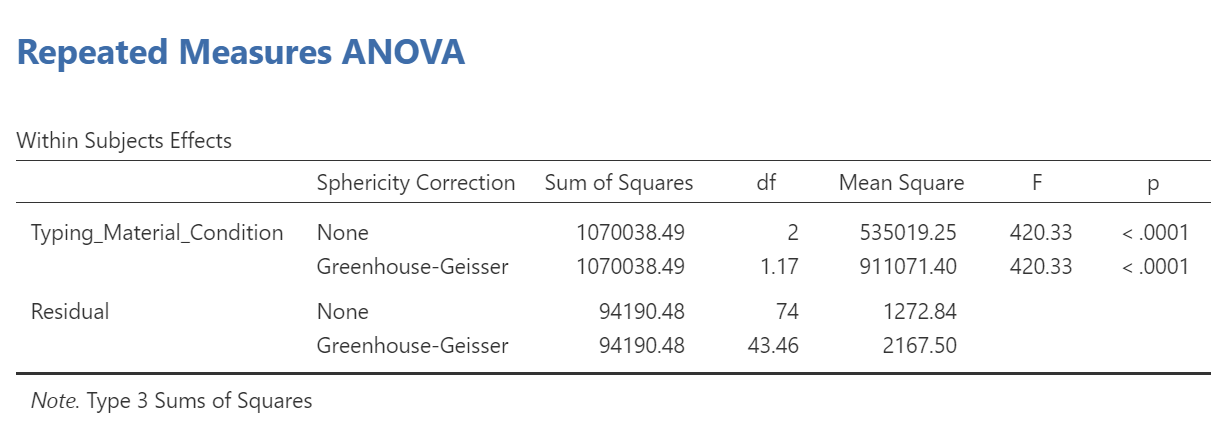
To make it easier for you to read, let’s cover any information that we will not use in our interpretation of the results.

From this table, we see that there is a significant effect of stimulus (or typing material) on reaction time because p < .0001. We might say it more formally as follows:
A one-way repeated measures ANOVA was conducted, and Greenhouse-Geisser estimates of sphericity were used to correct the degrees of freedom (ε = .59) because Mauchly’s test indicated a violation to the assumption, p < .05. The mean reaction times were significantly different among the types of stimulus, F(1.17, 43.46) = 420.33, p < .0001.
Have a look at the two tables from which these results were taken. Can you see where these statistics were taken from?
Remember this is an omnibus ANOVA result. We do not know how many differences among means exist or between which means they would be found.
In order to graph this data and look at the means, go to back into the analysis commands. Remember, you can do this by clicking on the results generated in the Results pane. The commands will appear on the left of your JAMOVI file. Now, scroll down to the “Estimated Marginal Means” ribbon. Move the factor (in our example, Typing_Material_Condition, to the Marginal Means window under “Term 1”. Then, under “Output”, select Marginal means plot and Marginal means tables.
In the Results pane, you should now see a graph and a table.
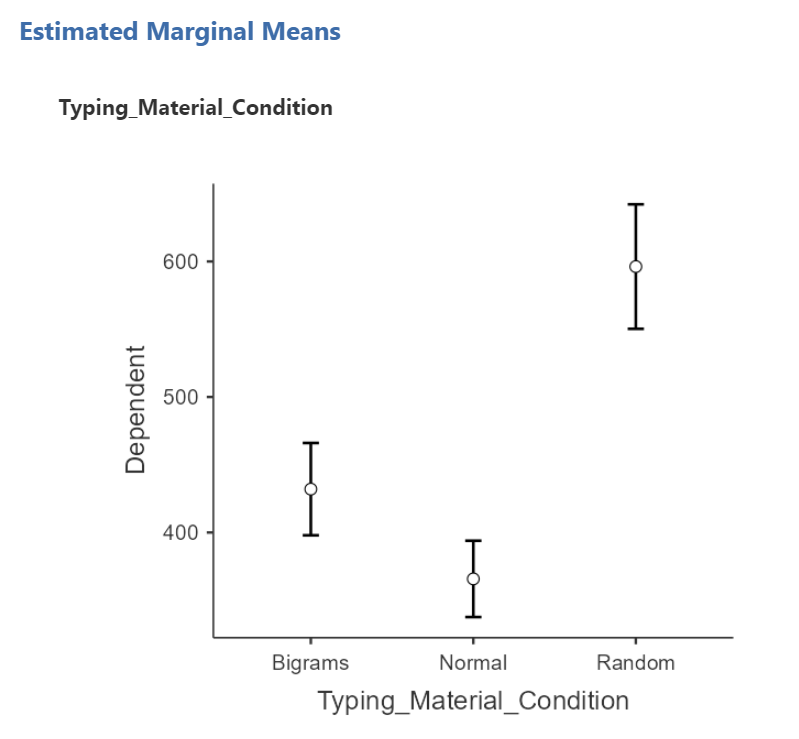
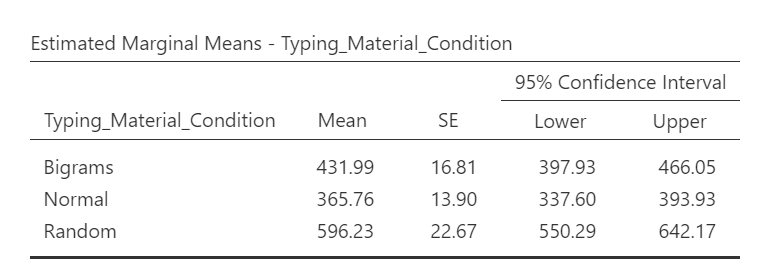
Think about an answer to this question: Looking at the graph and considering the mean of each level, where would you guess at least one significant difference in mean reaction times between stimulus levels might be found?
To the best of our knowledge, there is currently no way to request a bar graph depicting all three means using JAMOVI.
8.7.4 Conduct follow-up tests
8.7.4.1 Planned comparisons
If you had a priori hypotheses about where the difference(s) may be, you would conduct planned comparisons. In JAMOVI, there is no easy way for us to request these planned comparisons because there are no built-in or programmed contrasts, and there is no way to chunk variance. As such, you would do conduct planned comparisons in JAMOVI by conducting paired-samples t-tests because, in each comparison, the reactions times are being measured from the same people.
8.7.4.2 Post-hoc tests
If you had no a priori hypotheses about where the difference(s) may be, you would conduct unplanned comparisons, or post-hoc tests. To find out where the difference among these 3 conditions exists, we will use post-hoc tests.
We could go through the menus again to request the post-hoc tests, or we could simplify the output in the Results pane by clicking on the Results to have the commands pop up to the left. Let’s do the latter. Next, scroll down to the “Post Hoc Tests” ribbon, move the factor (Typing_Material_Condition) to the window on the right, and then select the correction you want applied. Let’s select Bonferroni.
JAMOVI will produce a new table in the Results pane. It will appear before the graph JAMOVI created based on commands entered previously.
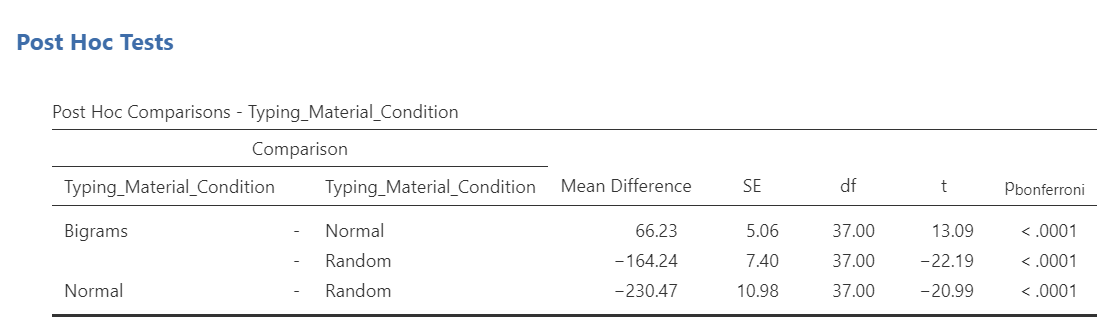
Before reading ahead, think about this: We had already written information about the results of the omnibus ANOVA. What would we now add to this write-up to help readers understand the significant result in more detail?
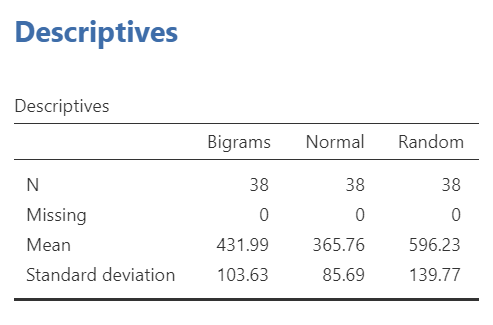
If we wish to view and report the descriptive statistics, we could find the mean reaction times for each level (typing material condition), as well as the 95% confidence interval, in the “Estimated Marginal Means” table in the Results pane. This table does not give us the standard deviation, though. To get the standard deviations, use the commands with which you are familiar: Analyses, Exploration, and Descriptives.
To get the effect sizes, you will need to calculate Cohen’s d. An appropriate formula to use follows:
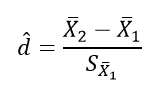
We will need to calculate the effect size for each comparison we will report. Remember, there were three unique comparisons. We can take the mean difference from the “Post Hoc Comparisons” table or fill in each pair of means and take the difference. The calculation of effect size for the comparison between the Bigram and Normal conditions follows:

The calculation of effect size for the comparison between the Bigram and Random conditions follows:
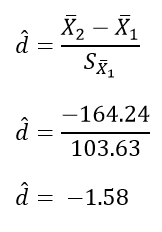
The calculation of effect size for the comparison between the Normal and Normal conditions follows:
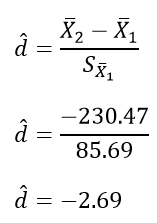
Based on the statistics presented in tables presented in this section, we would add to what we had already formally written about the omnibus ANOVA and construct a Results section something like this:
A one-way repeated measures ANOVA was conducted, and Greenhouse-Geisser estimates of sphericity were used to correct the degrees of freedom (ε = .59) because Mauchly’s test indicated a violation to the assumption, p < .05. The mean reaction times were significantly different among the types of stimulus, F(1.17, 43.46) = 420.33, p < .0001. Post-hoc pairwise comparisons with Bonferroni corrections were performed. It was found that mean reaction time in the Bigram condition (M = 431.99, SD = 103.63, 95% CI [397.93, 466.05]) was significantly different from that in the Normal condition (M = 365.76, SD = 85.69, 95% CI [337.60, 393.93]), p < .0001, d = 0.64, and the mean reaction time in the Bigram condition was also significantly different from that in the Random condition (M = 596.23, SD = 139.77, 95% CI [550.29, 642.29]), p < .0001, d = -1.58. Furthermore, the mean reaction time in the Normal condition was significantly different from that in the Random condition, p < .0001, d = -2.69.
8.7.5 Some APA formatting reminders for writing results sections
Always note the name of the test you performed (in this case, one-way analysis of variance, or ANOVA) and whether the result is significant or non-significant (Note: We do not use the word insignificant.).
We usually round to two decimal places, except for p-values. If your p-value was .0001, it would be okay to write p = .0001 or p < .001.
Do not include a leading 0 before the decimal for the p-value (p = .001 not p = 0.001, or p < .05 not p < 0.05) or before ε (ex. ε = .59 not ε = 0.59).
Yes, I’m serious. No, I don’t know why. Yes, it does seem a bit silly. Yes, you lose points if you don’t adhere to APA format when requested to do so.
Pay attention to spaces, parentheses, etc. APA is very picky about that. For example, it’s F(3, 35.75) = 6.08 not F(3,35.75)=6.08. There are spaces on either side of =, >, or < symbols.
Italicize symbols such as M, SD, p, t, d, and F.
8.7.6 Homework
See Moodle.
8.7.7 Practice Problems
In the lab demonstration, we saw that the assumption of sphericity was violated. Try changing data points until the assumption is upheld.
In the lab demonstration, we saw that the assumption of sphericity was violated. Try changing data points until the assumption is upheld while aiming to minimize the changes you make overall.
Use the Mean Accuracy Scores 2 data set to practice checking assumptions and running a repeated measures ANOVA with follow-up testsing.
When we discussed t-tests, we talked about the Mehr, Song, and Spelke (2016) study. Have a look at that data set, and try to develop a research question that might be answered with a repeated measures ANOVA. (Hint: It is okay to use only the variable name, rather than the phrase for what was measured, in your research question.)